





Faut-il compiler Tensorflow ?
En seulement deux ans, Tensorflow™ est devenu l’une des bibliothèques les plus populaires pour le deep machine learning. Il est essentiel d’atteindre les performances les plus élevées possibles lorsque vous travaillez sur des projets Tensorflow™, comme pour le développement de tout autre produit logiciel.
L’un des moyens efficaces pour augmenter la vitesse de calcul, conseillé par Google, est d’éviter d’utiliser un package précompilé de la bibliothèque Tensorflow™ et de le remplacer par la version Tensorflow™ compilée directement à partir du code source. Récemment, une étude a été menée afin de tester la méthode proposée par Google, dans le cadre de laquelle les mêmes projets ont été lancés en utilisant Tensorflow™ sans prise en charge de la plateforme CUDA® installée, de trois manières différentes :
- Utilisation d’un package précompilé ;
- Compilation directe à partir du code source sans prise en charge des instructions CPU ;
- Compilation directe à partir du code source avec prise en charge des instructions CPU (AVX, AVX2 et FMA, etc.).
Des tests de la bibliothèque Tensorflow™ avec prise en charge de la plate-forme CUDA® ont également été réalisés. Les résultats des tests suivants ont été pris comme références :
- Tests avec des données réelles. Un réseau de type Inception-ResNet-v2 a été utilisé et entraîné pour reconnaître le sexe des personnes à l’aide du jeu de données FaceScrub (http://vintage.winklerbros.net/facescrub.html).
- Tests synthétiques du site officiel de TensorFlow™. Le modèle de réseau neuronal est Inception v3 (https://www.tensorflow.org/lite/performance/measurement).
Les tests ont été effectués sur le serveur avec la configuration suivante (www.leadergpu.fr) :
- GPU: NVIDIA® Tesla® P100 (16 GB)
- CPU: 2 x Intel® Xeon® E5-2630v4 2.2 GHz
- RAM: 128 GB
- SSD: 960 GB
- Ports: 40 Gbps
- OS: CentOS 7
- Python 2.7
- TensorFlow™ 1.3
Commandes pour installer Tensorflow™ sans prise en charge de CUDA® :
Installation de Tensorflow™ à partir d’un package précompilé :
# pip install tensorflowInstallation de Tensorflow™ compilé directement à partir du code source :
# git clone https://github.com/tensorflow/tensorflow
# cd tensorflow
# git checkout r1.3
# ./configure-
pour la compilation sans prise en charge des commandes CPU :
# bazel build -c opt //tensorflow/tools/pip_package:build_pip_package -
pour la compilation avec prise en charge des commandes CPU :
# bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.1 --copt=-msse4.2 //tensorflow/tools/pip_package:build_pip_package bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg # pip install /tmp/tensorflow_pkg/1.3.0-cp27-cp27mu-linux_x86_64.whl
Tests sur données réelles et données synthétiques sans prise en charge de CUDA
Commandes pour démarrer un réseau pour des tests avec des données réelles :
# cd gender_net
# python download_data.py
# python convert_data_FS.py
# time python model_FS_mulGPU_v3.pyCommandes pour exécuter des tests avec des données synthétiques :
# mkdir ~/Anaconda
# cd ~/Anaconda
# git clone https://github.com/tensorflow/benchmarks.git
# cd ~/Anaconda/benchmarks/scripts/tf_cnn_benchmarks
# python tf_cnn_benchmarks.py --devicecpu model --inception3 --batch_size 32 --data_format NHWC --num_batches 40
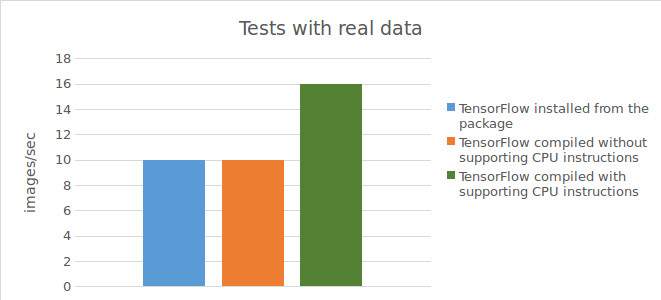
Test de Tensorflow™ installé à partir d’un package précompilé :
Résultat des tests avec des données réelles :
10 images / sec;
temps d’exécution du script de test
= 20m55s.
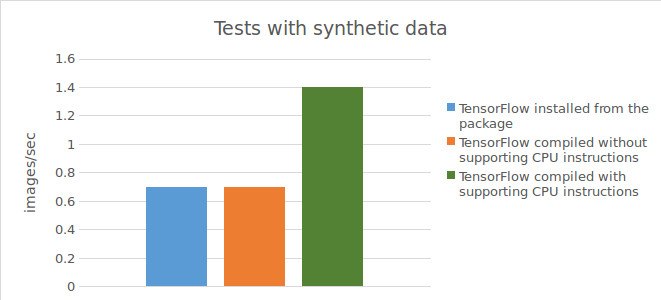
Résultat des tests avec des données synthétiques :
0,73 images/sec;
temps d’exécution du script de test
= 36m25s.
Test de Tensorflow™ compilé directement à partir du code source sans prise en charge des instructions CPU :
Résultat des tests avec des données réelles :
10 images/sec;
temps d’exécution du script de test
= 20m55s.
Résultat des tests avec des données synthétiques :
0,74 images/sec;
temps d’exécution du script de test
= 36m21s.
Test de Tensorflow™ compilé directement à partir du code source avec prise en charge des instructions CPU :
Résultat des tests avec des données réelles :
15-16 images/sec;
temps d’exécution du script de test
= 14m13s.
Résultat des tests avec des données synthétiques :
1,44 images/sec;
temps d’exécution du script de test
= 18m40s.
Vous trouverez ci-dessous un tableau montrant les résultats des tests.
Commandes d’installation de Tensorflow™ avec prise en charge de CUDA :
Installation de Tensorflow™ à partir d’un package précompilé :
# pip install tensorflowInstallation de Tensorflow™ compilé directement à partir du code source :
# git clone https://github.com/tensorflow/tensorflow
# cd tensorflow
# git checkout r1.3
#./configure
# bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.1 --copt=-msse4.2 --config=cuda //tensorflow/tools/pip_package:build_pip_package
bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
# pip install /tmp/tensorflow_pkg/1.3.0-cp27-cp27mu-linux_x86_64.whlLes commandes de démarrage des réseaux sont similaires aux commandes des tests précédents à l’exception de la commande d’exécution du script pour commencer à entraîner le réseau sur des données synthétiques :
# python tf_cnn_benchmarks.py --num_gpus=1 --model inception3 --batch_size 32Tests sur données réelles et données synthétiques avec prise en charge de CUDA
Test de Tensorflow™ installé à partir d’un package précompilé :
Résultat des tests avec des données réelles :
214 images/sec.
Résultat des tests avec des données synthétiques :
126,33 images/sec.
Test de Tensorflow™ compilé directement à partir du code source avec prise en charge des instructions CPU :
Résultat des tests avec des données réelles :
215 images/sec.
Résultat des tests avec des données synthétiques :
126,34 images/sec.
Pour résumer les résultats des tests réalisés, l’utilisation de Tensorflow™ compilé directement à partir du code source (avec prise en charge des instructions CPU) permet d’obtenir une augmentation significative de l’accélération (1,5 fois avec des données réelles et le double avec des données synthétiques) lors de l’exécution de calculs sur le CPU. Cependant, avec un GPU, l’utilisation de Tensorflow™ compilé directement à partir du code source n’a pas permis d’obtenir une amélioration des résultats par rapport à Tensorflow™ installé à partir du package précompilé.