





PrivateGPT : L'IA pour les documents

Les grands modèles linguistiques ont beaucoup évolué ces dernières années et sont devenus des outils efficaces pour de nombreuses tâches. Le seul problème lié à leur utilisation est que la plupart des produits basés sur ces modèles utilisent des services prêts à l'emploi d'entreprises tierces. Cette utilisation peut entraîner la fuite de données sensibles, c'est pourquoi de nombreuses entreprises évitent de télécharger des documents internes dans des services LLM publics.
Un projet comme PrivateGPT pourrait être une solution. Il est initialement conçu pour un usage entièrement local. Sa force réside dans le fait que vous pouvez soumettre divers documents en entrée, et le réseau neuronal les lira pour vous et fournira ses propres commentaires en réponse à vos demandes. Par exemple, vous pouvez lui faire parvenir des textes volumineux et lui demander de tirer des conclusions sur la base de la demande de l'utilisateur. Cela vous permet d'économiser considérablement du temps sur la relecture.
C'est particulièrement vrai dans des domaines professionnels comme la médecine. Par exemple, un médecin peut poser un diagnostic et demander au réseau neuronal de le confirmer sur la base de l'ensemble des documents téléchargés. Cela permet d'obtenir un avis indépendant supplémentaire et de réduire ainsi le nombre d'erreurs médicales. Comme les demandes et les documents ne quittent pas le serveur, on peut être sûr que les données reçues n'apparaîtront pas dans le domaine public.
Aujourd'hui, nous allons vous montrer comment déployer un réseau neuronal sur des serveurs dédiés LeaderGPU avec le système d'exploitation Ubuntu 22.04 LTS en seulement 20 minutes.
Préparation du système
Commencez par mettre à jour vos paquets vers la dernière version :
sudo apt update && sudo apt -y upgradeInstallez maintenant des paquets supplémentaires, des bibliothèques et le pilote graphique NVIDIA®. Tous ces éléments seront nécessaires pour construire le logiciel et l'exécuter sur le GPU :
sudo apt -y install build-essential git gcc cmake make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev zlib1g-dev libncursesw5-dev libgdbm-dev libc6-dev zlib1g-dev libsqlite3-dev tk-dev libssl-dev openssl libffi-dev lzma liblzma-dev libbz2-devInstallation de CUDA® 12.4
En plus du pilote, vous devez installer le kit d'outils NVIDIA® CUDA®. Ces instructions ont été testées sur CUDA® 12.4, mais tout devrait également fonctionner sur CUDA® 12.2. Cependant, gardez à l'esprit que vous devrez indiquer la version installée lorsque vous spécifierez le chemin d'accès aux fichiers exécutables.
Exécutez la commande suivante de manière séquentielle :
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinsudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.debsudo dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.debsudo cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/sudo apt-get update && sudo apt-get -y install cuda-toolkit-12-4Vous trouverez plus d'informations sur l'installation de CUDA® dans notre base de connaissances. Redémarrez le serveur :
sudo shutdown -r nowPyEnv install
Il est temps d'installer un simple utilitaire de contrôle de version Python appelé PyEnv. Il s'agit d'une version améliorée du projet similaire pour Ruby (rbenv), configuré pour fonctionner avec Python. Il peut être installé avec un script d'une ligne :
curl https://pyenv.run | bashVous devez maintenant ajouter quelques variables à la fin du fichier script, qui est exécuté lors de la connexion. Les trois premières lignes sont responsables du bon fonctionnement de PyEnv, et la quatrième est nécessaire pour Poetry, qui sera installé plus tard :
nano .bashrcexport PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
export PATH="/home/usergpu/.local/bin:$PATH"Appliquez les réglages que vous avez effectués :
source .bashrcInstaller la version 3.11 de Python :
pyenv install 3.11Créer un environnement virtuel pour Python 3.11 :
pyenv local 3.11Installation de Poetry
La prochaine pièce du puzzle est Poetry. Il s'agit d'un analogue de pip pour la gestion des dépendances dans les projets Python. L'auteur de Poetry était fatigué d'avoir constamment affaire à différentes méthodes de configuration, telles que setup.cfg, requirements.txt, MANIFEST.ini, et d'autres. C'est ce qui a motivé le développement d'un nouvel outil qui utilise un fichier pyproject.toml, qui stocke toutes les informations de base sur un projet, et pas seulement une liste de dépendances.
Installer la poésie :
curl -sSL https://install.python-poetry.org | python3 -PrivateGPT install
Maintenant que tout est prêt, vous pouvez cloner le dépôt PrivateGPT :
git clone https://github.com/imartinez/privateGPTAllez sur le dépôt téléchargé :
cd privateGPTExécuter l'installation des dépendances à l'aide de Poetry tout en activant les composants supplémentaires :
- ui - ajoute une interface web de gestion basée sur Gradio à l'application dorsale ;
- embedding-huggingface - permet d'intégrer des modèles téléchargés depuis HuggingFace;
- llms-llama-cpp - ajoute la prise en charge de l'inférence directe des modèles au format GGUF ;
- vector-stores-qdrant - ajoute la base de données vectorielle qdrant.
poetry install --extras "ui embeddings-huggingface llms-llama-cpp vector-stores-qdrant"Définissez votre jeton d'accès à Hugging Face. Pour plus d'informations, veuillez lire cet article:
export HF_TOKEN="YOUR_HUGGING_FACE_ACCESS_TOKEN"Maintenant, exécutez le script d'installation, qui téléchargera automatiquement le modèle et les poids (Meta Llama 3.1 8B Instruct par défaut) :
poetry run python scripts/setupLa commande suivante recompile llms-llama-cpp séparément pour activer la prise en charge de NVIDIA® CUDA®, afin de décharger les charges de travail sur le GPU :
CUDACXX=/usr/local/cuda-12/bin/nvcc CMAKE_ARGS="-DGGML_CUDA=on -DCMAKE_CUDA_ARCHITECTURES=native" FORCE_CMAKE=1 pip install llama-cpp-python --no-cache-dir --force-reinstall --upgradeSi vous obtenez une erreur du type nvcc fatal : Unsupported gpu architecture 'compute_', indiquez simplement l'architecture exacte du GPU que vous utilisez. Par exemple : DCMAKE_CUDA_ARCHITECTURES=86 pour NVIDIA® RTX™ 3090.
La dernière étape avant de commencer est d'installer le support pour les appels asynchrones (async/await) :
pip install asyncioPrivateGPT run
Exécute PrivateGPT à l'aide d'une seule commande :
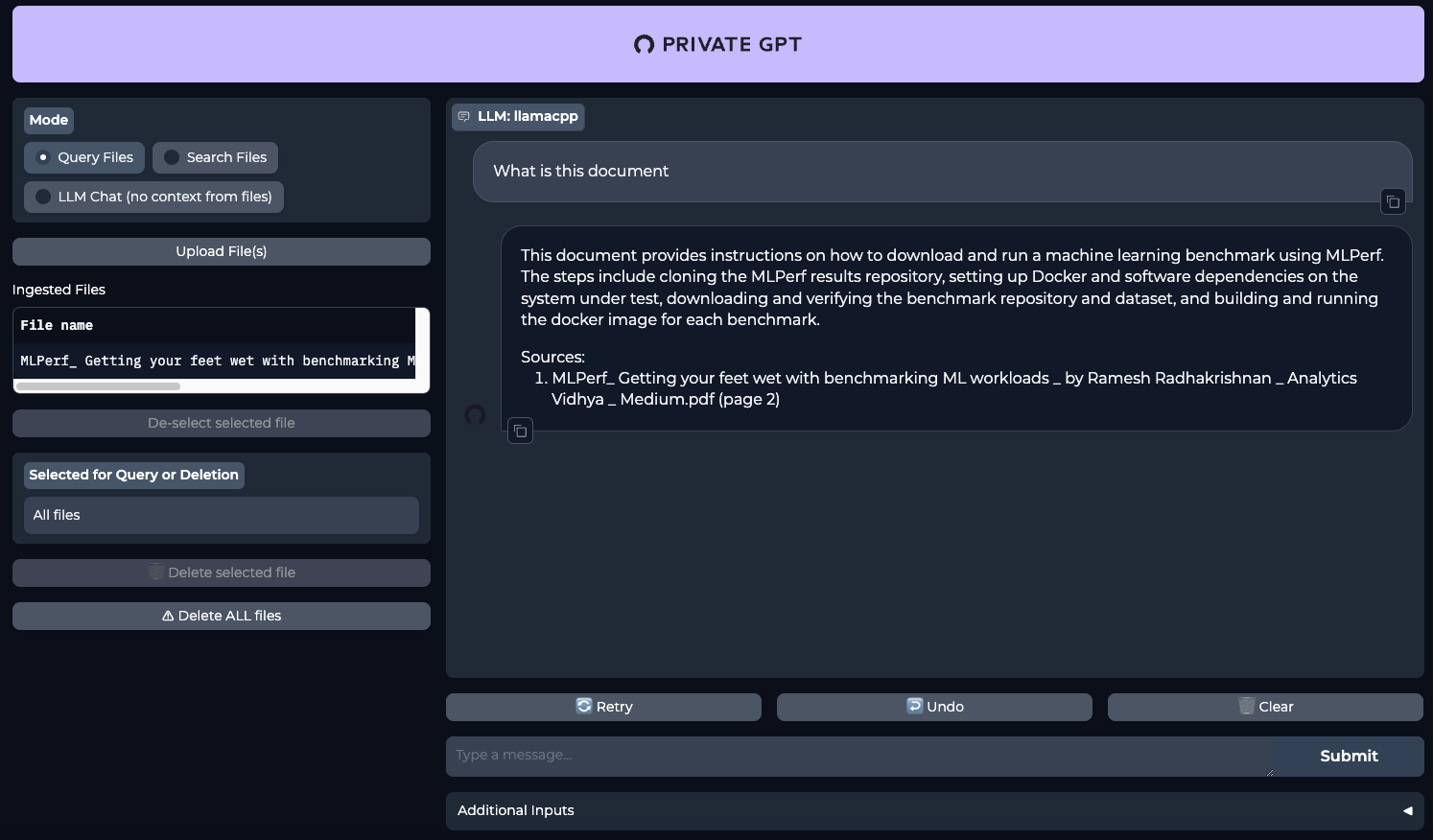
make runOuvrez votre navigateur web et allez à la page http://[LeaderGPU_server_IP_address]:8001
Voir aussi:
Mis à jour: 04.01.2026
Publié: 20.01.2025




