





Langflow, créateur d'applications d'IA à code réduit
Le développement de logiciels a évolué de manière spectaculaire ces dernières années. Les programmeurs modernes ont désormais accès à des centaines de langages et de cadres de programmation. Au-delà des approches impératives et déclaratives traditionnelles, une nouvelle méthode passionnante de création d'applications est en train d'émerger. Cette approche innovante exploite la puissance des réseaux neuronaux, ouvrant ainsi de fantastiques possibilités aux développeurs.
Les gens se sont habitués aux assistants IA dans les IDE qui aident à l'autocomplétion du code et aux réseaux neuronaux modernes qui génèrent facilement du code pour de simples jeux en Python. Cependant, de nouveaux outils hybrides émergent et pourraient révolutionner le paysage du développement. L'un de ces outils est Langflow.
Langflow a de multiples fonctions. Pour les développeurs professionnels, il offre un meilleur contrôle sur des systèmes complexes tels que les réseaux neuronaux. Pour les personnes peu familiarisées avec la programmation, il permet de créer des applications simples mais pratiques. Ces objectifs sont atteints par différents moyens, que nous allons explorer plus en détail.
Réseaux neuronaux
Le concept de réseau neuronal peut être simplifié pour les utilisateurs. Imaginez une boîte noire qui reçoit des données d'entrée et des paramètres influençant le résultat final. Cette boîte traite les données d'entrée à l'aide d'algorithmes complexes, souvent qualifiés de "magiques", et produit des données de sortie qui peuvent être présentées à l'utilisateur.
Le fonctionnement interne de cette boîte noire varie en fonction de la conception du réseau neuronal et des données d'entraînement. Il est essentiel de comprendre que les développeurs et les utilisateurs ne peuvent jamais obtenir des résultats sûrs à 100 %. Contrairement à la programmation traditionnelle où 2 + 2 est toujours égal à 4, un réseau neuronal peut donner cette réponse avec 99 % de certitude, tout en conservant une marge d'erreur.
Le contrôle du processus de "réflexion" d'un réseau neuronal est indirect. Nous ne pouvons ajuster que certains paramètres, comme la "température". Ce paramètre détermine le degré de créativité ou de contrainte du réseau neuronal dans son approche. Une valeur de température basse limite le réseau à une approche plus formelle et structurée des tâches et des solutions. À l'inverse, des valeurs de température élevées accordent au réseau une plus grande liberté, ce qui peut l'amener à s'appuyer sur des faits moins fiables, voire à créer des informations fictives.
Cet exemple illustre la manière dont les utilisateurs peuvent influencer le résultat final. Pour la programmation traditionnelle, cette incertitude constitue un défi important : des erreurs peuvent apparaître de manière inattendue et les résultats spécifiques deviennent imprévisibles. Cependant, cette imprévisibilité est avant tout un problème pour les ordinateurs, et non pour les humains qui peuvent s'adapter à des résultats variables et les interpréter.
Si les résultats d'un réseau neuronal sont destinés à un être humain, la formulation spécifique utilisée pour les décrire est généralement moins importante. Compte tenu du contexte, les gens peuvent interpréter correctement divers résultats du point de vue de la machine. Alors que des concepts tels que "valeur positive", "résultat obtenu" ou "décision positive" peuvent signifier à peu près la même chose pour une personne, la programmation traditionnelle aurait du mal à gérer cette flexibilité. Elle devrait tenir compte de toutes les variations possibles des réponses, ce qui est pratiquement impossible.
En revanche, si la suite du traitement est confiée à un autre réseau neuronal, celui-ci peut comprendre et traiter correctement le résultat obtenu. Sur cette base, il peut alors formuler sa propre conclusion avec un certain degré de confiance, comme nous l'avons mentionné plus haut.
Code bas
La plupart des langages de programmation impliquent l'écriture de code. Les programmeurs créent la logique de chaque partie d'une application dans leur esprit, puis la décrivent à l'aide d'expressions spécifiques au langage. Ce processus forme un algorithme : une séquence claire d'actions menant à un résultat spécifique et prédéterminé. Il s'agit d'une tâche complexe qui nécessite un effort mental important et une compréhension approfondie des capacités du langage.
Cependant, il n'est pas nécessaire de réinventer la roue. De nombreux problèmes rencontrés par les développeurs modernes ont déjà été résolus de diverses manières. Des extraits de code pertinents peuvent souvent être trouvés sur StackOverflow. La programmation moderne peut être comparée à l'assemblage d'un tout à partir de pièces de différents jeux de construction. Le système Lego offre un modèle réussi, ayant standardisé différents jeux de pièces pour assurer la compatibilité.
La méthode de programmation low-code suit un principe similaire. Différents éléments de code sont modifiés pour s'adapter parfaitement les uns aux autres et sont présentés aux développeurs sous forme de blocs prêts à l'emploi. Chaque bloc peut avoir des entrées et des sorties de données. La documentation spécifie la tâche que chaque type de bloc résout et le format dans lequel il accepte ou produit des données.
En connectant ces blocs dans une séquence spécifique, les développeurs peuvent former l'algorithme d'une application et visualiser clairement sa logique opérationnelle. L'exemple le plus connu de cette méthode de programmation est sans doute la méthode graphique de la tortue, couramment utilisée dans les établissements d'enseignement pour présenter les concepts de programmation et développer la pensée algorithmique.
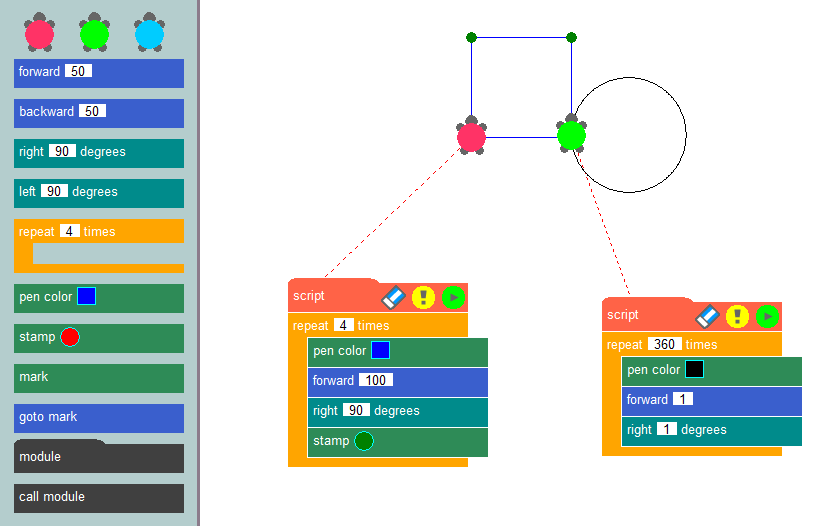
L'essence de cette méthode est simple : il s'agit de dessiner des images sur l'écran à l'aide d'une tortue virtuelle qui laisse une trace en rampant sur la toile. En utilisant des blocs prêts à l'emploi, tels que le déplacement d'un nombre déterminé de pixels, la rotation à des angles spécifiques ou l'élévation et l'abaissement du stylo, les développeurs peuvent créer des programmes qui dessinent les images qu'ils souhaitent. La création d'applications à l'aide d'un constructeur à code bas est similaire aux graphiques de tortue, mais elle permet aux utilisateurs de résoudre un large éventail de problèmes, et pas seulement de dessiner sur un canevas.
C'est l'outil de programmation Node-RED d'IBM qui a le mieux mis en œuvre cette méthode. Il a été développé comme un moyen universel de garantir le fonctionnement conjoint de divers appareils, services en ligne et API. L'équivalent des extraits de code étaient des nœuds de la bibliothèque standard (palette).

Les capacités de Node-RED peuvent être étendues en installant des modules complémentaires ou en créant des nœuds personnalisés qui exécutent des actions de données spécifiques. Les développeurs placent les nœuds de la palette sur le bureau et établissent des relations entre eux. Ce processus crée la logique de l'application, la visualisation aidant à maintenir la clarté.
En ajoutant les réseaux neuronaux à ce concept, on obtient un système fascinant. Au lieu de traiter les données à l'aide de formules mathématiques spécifiques, vous pouvez les introduire dans un réseau neuronal et spécifier la sortie souhaitée. Bien que les données d'entrée puissent varier légèrement à chaque fois, les résultats peuvent être interprétés par des humains ou d'autres réseaux neuronaux.
Génération augmentée par récupération (RAG)
La précision des données dans les grands modèles linguistiques est une préoccupation urgente. Ces modèles reposent uniquement sur les connaissances acquises au cours de la formation, qui dépendent de la pertinence des ensembles de données utilisés. Par conséquent, les grands modèles linguistiques peuvent ne pas disposer de suffisamment de données pertinentes, ce qui peut conduire à des résultats erronés.
Pour résoudre ce problème, des méthodes de mise à jour des données sont nécessaires. Permettre aux réseaux neuronaux d'extraire le contexte de sources supplémentaires, telles que des sites web, peut améliorer de manière significative la qualité des réponses. C'est précisément ainsi que fonctionne la méthode RAG (Retrieval-Augmented Generation). Les données supplémentaires sont converties en représentations vectorielles et stockées dans une base de données.
En fonctionnement, les modèles de réseaux neuronaux peuvent convertir les demandes des utilisateurs en représentations vectorielles et les comparer à celles stockées dans la base de données. Lorsque des vecteurs similaires sont trouvés, les données sont extraites et utilisées pour former une réponse. Les bases de données vectorielles sont suffisamment rapides pour prendre en charge ce système en temps réel.
Pour que ce système fonctionne correctement, il faut établir une interaction entre l'utilisateur, le modèle de réseau neuronal, les sources de données externes et la base de données vectorielles. Langflow simplifie cette configuration grâce à sa composante visuelle - les utilisateurs construisent simplement des blocs standard et les "relient", créant ainsi un chemin pour le flux de données.
La première étape consiste à alimenter la base de données vectorielles avec les sources pertinentes. Il peut s'agir de fichiers provenant d'un ordinateur local ou de pages web provenant d'Internet. Voici un exemple simple de chargement de données dans la base de données :
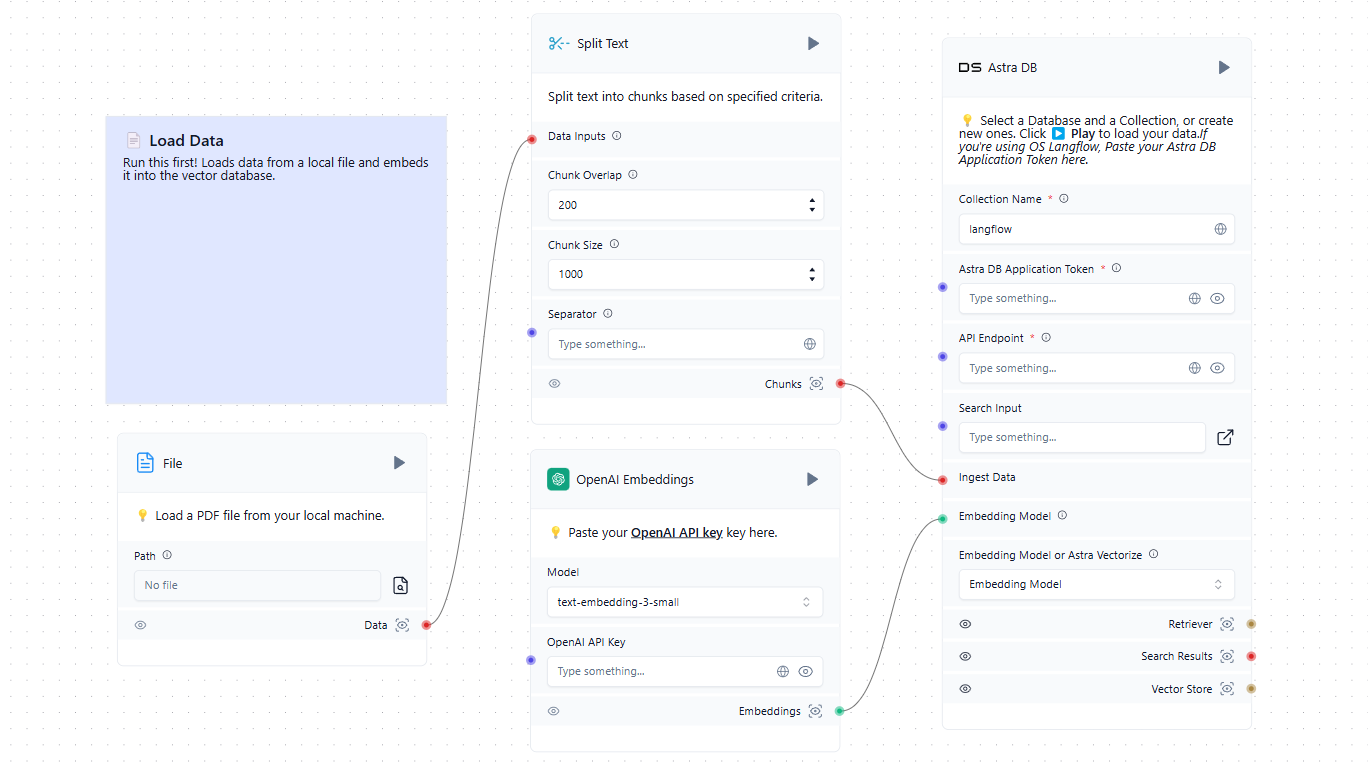
Maintenant que nous disposons d'une base de données vectorielle en plus du LLM formé, nous pouvons l'incorporer dans le schéma général. Lorsqu'un utilisateur soumet une requête dans le chat, il forme simultanément une invite et interroge la base de données vectorielle. Si des vecteurs similaires sont trouvés, les données extraites sont analysées et ajoutées en tant que contexte à l'invite formée. Le système envoie ensuite une requête au réseau neuronal et transmet la réponse reçue à l'utilisateur dans le chat.
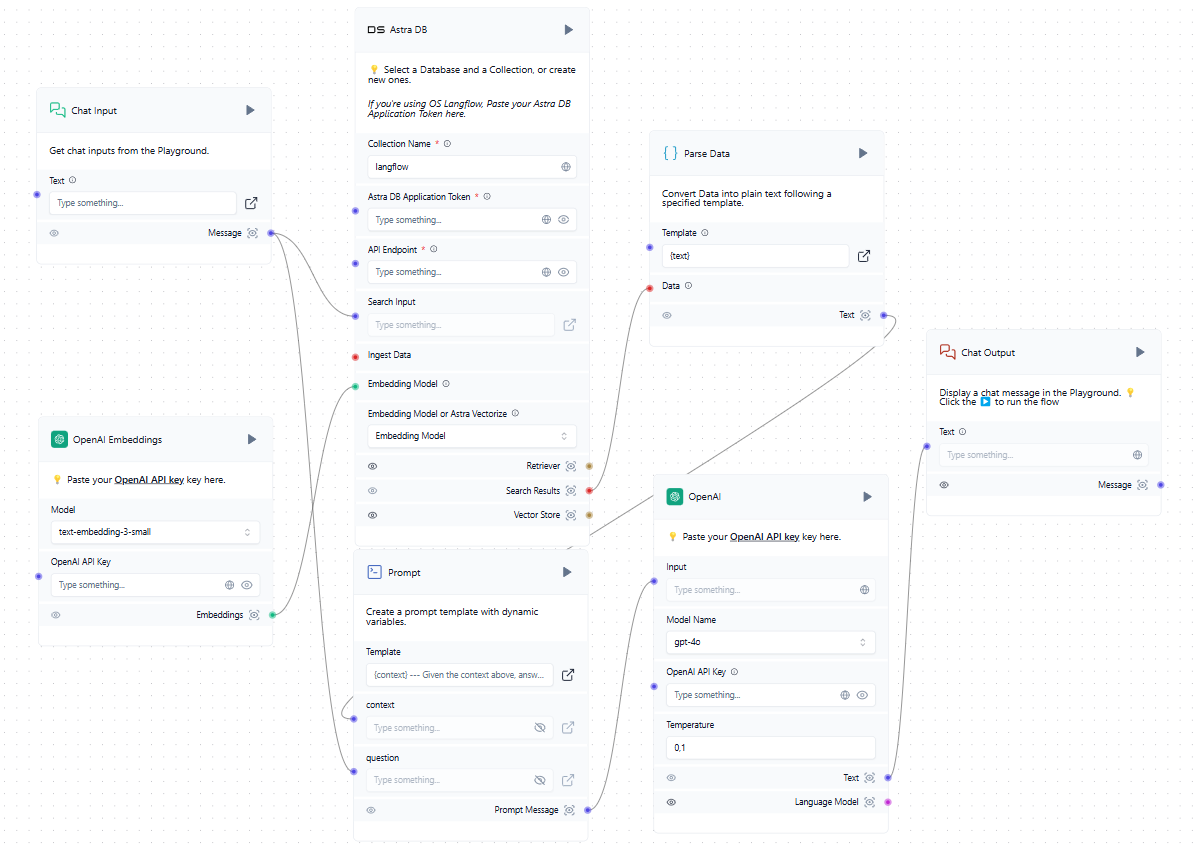
Bien que l'exemple mentionne des services en nuage tels qu'OpenAI et AstraDB, vous pouvez utiliser n'importe quel service compatible, y compris ceux déployés localement sur les serveurs LeaderGPU. Si vous ne trouvez pas l'intégration dont vous avez besoin dans la liste des blocs disponibles, vous pouvez l'écrire vous-même ou ajouter un bloc créé par quelqu'un d'autre.
Démarrage rapide
Préparation du système
La façon la plus simple de déployer Langflow est de le faire dans un conteneur Docker. Pour configurer le serveur, commencez par installer Docker Engine. Ensuite, mettez à jour le cache de paquets et les paquets avec leurs dernières versions :
sudo apt update && sudo apt -y upgradeInstaller les paquets supplémentaires requis par Docker :
sudo apt -y install apt-transport-https ca-certificates curl software-properties-commonTélécharger la clé GPG pour ajouter le dépôt officiel de Docker :
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgAjoutez le dépôt à APT en utilisant la clé que vous avez téléchargée et installée précédemment :
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullActualiser la liste des paquets :
sudo apt updatePour s'assurer que Docker sera installé à partir du dépôt nouvellement ajouté et non à partir de celui du système, vous pouvez exécuter la commande suivante :
apt-cache policy docker-ceInstaller le moteur Docker :
sudo apt install docker-ceVérifiez que Docker a été installé avec succès et que le démon correspondant est en cours d'exécution et dans l'état active (running):
sudo systemctl status docker● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset>
Active: active (running) since Mon 2024-11-18 08:26:35 UTC; 3h 27min ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Main PID: 1842 (dockerd)
Tasks: 29
Memory: 1.8G
CPU: 3min 15.715s
CGroup: /system.slice/docker.service
Construire et exécuter
Tout est prêt pour construire et exécuter un conteneur Docker avec Langflow. Cependant, il y a une mise en garde : au moment de la rédaction de ce guide, la dernière version (taguée v1.1.0) a une erreur et ne démarre pas. Pour éviter ce problème, nous utiliserons la version précédente, v1.0.19.post2, qui fonctionne parfaitement dès son téléchargement.
L'approche la plus simple consiste à télécharger le dépôt du projet depuis GitHub :
git clone https://github.com/langflow-ai/langflowNaviguez jusqu'au répertoire contenant l'exemple de configuration de déploiement :
cd langflow/docker_exampleVous devez maintenant faire deux choses. Tout d'abord, modifiez la balise release afin qu'une version fonctionnelle (au moment de la rédaction de ces instructions) soit construite. Deuxièmement, ajoutez une autorisation simple afin que personne ne puisse utiliser le système sans connaître le login et le mot de passe.
Ouvrez le fichier de configuration :
sudo nano docker-compose.ymlau lieu de la ligne suivante :
image: langflowai/langflow:latestspécifier la version au lieu de la balise latest:
image: langflowai/langflow:v1.0.19.post2Vous devez également ajouter trois variables à la section environment:
- LANGFLOW_AUTO_LOGIN=false
- LANGFLOW_SUPERUSER=admin
- LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordLa première variable désactive l'accès à l'interface web sans autorisation. La deuxième ajoute le nom d'utilisateur qui recevra les droits d'administrateur du système. La troisième ajoute le mot de passe correspondant.
Si vous prévoyez de stocker le fichier docker-compose.yml dans un système de contrôle de version, évitez d'écrire le mot de passe directement dans ce fichier. Créez plutôt un fichier distinct avec une extension .env dans le même répertoire et stockez-y la valeur de la variable.
LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordDans le fichier docker-compose.yml, vous pouvez désormais faire référence à une variable au lieu de spécifier directement un mot de passe :
LANGFLOW_SUPERUSER_PASSWORD=${LANGFLOW_SUPERUSER_PASSWORD}Pour éviter d'exposer accidentellement le fichier *.env sur GitHub, n'oubliez pas de l'ajouter à .gitignore. Votre mot de passe sera ainsi raisonnablement à l'abri d'un accès non désiré.
Il ne reste plus qu'à construire notre conteneur et à l'exécuter :
sudo docker compose upOuvrez la page web à http://[LeaderGPU_IP_address]:7860, et vous verrez le formulaire d'autorisation :
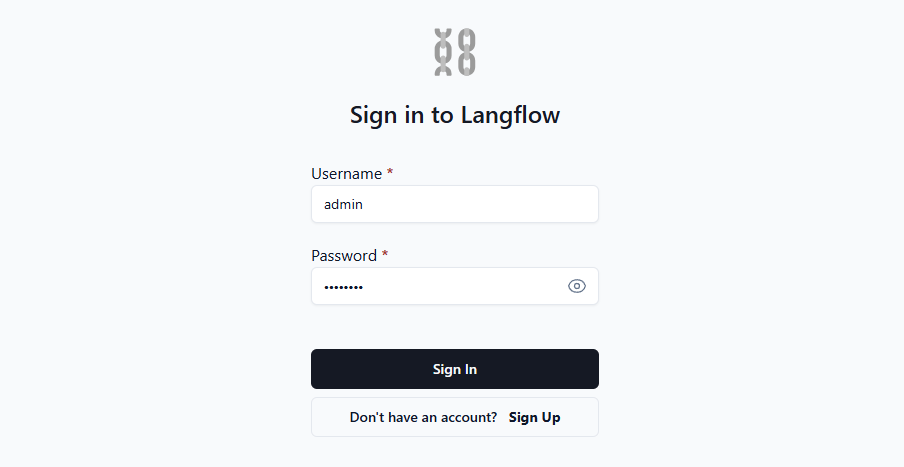
Une fois que vous avez saisi votre login et votre mot de passe, le système vous donne accès à l'interface web où vous pouvez créer vos propres applications. Pour des conseils plus approfondis, nous vous suggérons de consulter la documentation officielle. Elle fournit des détails sur diverses variables d'environnement qui permettent de personnaliser facilement le système en fonction de vos besoins.
Voir aussi:
Mis à jour: 04.01.2026
Publié: 22.01.2025




