





DeepSeek-R1 : l'avenir des LLM

Bien que les réseaux neuronaux génératifs se soient développés rapidement, leur progression est restée relativement stable ces dernières années. Cette situation a changé avec l'arrivée de DeepSeek, un réseau neuronal chinois qui a non seulement eu un impact sur le marché boursier, mais qui a également attiré l'attention des développeurs et des chercheurs du monde entier. Contrairement à d'autres grands projets, le code de DeepSeek a été publié sous la licence permissive MIT. Cette évolution vers l'open source a été saluée par la communauté, qui s'est empressée d'explorer les capacités du nouveau modèle.
L'aspect le plus impressionnant est que l'entraînement de ce nouveau réseau neuronal aurait coûté 20 fois moins cher que les concurrents offrant une qualité similaire. La formation du modèle n'a nécessité que 55 jours et 5,6 millions de dollars. La publication de DeepSeek a déclenché l'une des plus fortes baisses en une seule journée de l'histoire des marchés boursiers américains. Bien que les marchés se soient finalement stabilisés, l'impact a été considérable.
Cet article examine dans quelle mesure les titres des médias reflètent la réalité et explore les configurations LeaderGPU adaptées à l'installation de ce réseau neuronal.
Caractéristiques architecturales
DeepSeek a choisi une voie d'optimisation maximale, ce qui n'est pas surprenant compte tenu des restrictions à l'exportation imposées par la Chine aux États-Unis. Ces restrictions empêchent le pays d'utiliser officiellement les modèles de GPU les plus avancés pour le développement de l'IA.
Le modèle utilise la technologie Multi Token Prediction (MTP), qui prédit plusieurs jetons en une seule étape d'inférence au lieu d'un seul. Cela fonctionne grâce à un décodage parallèle des jetons combiné à des couches masquées spéciales qui maintiennent l'autorégressivité.
Les essais de MTP ont donné des résultats remarquables, augmentant les vitesses de génération de 2 à 4 fois par rapport aux méthodes traditionnelles. L'excellente évolutivité de la technologie la rend précieuse pour les applications actuelles et futures de traitement du langage naturel.
Le modèle Multi-Head Latent Attention (MLA) est doté d'un mécanisme d'attention amélioré. Lorsque le modèle construit de longues chaînes de raisonnement, il maintient une attention ciblée sur le contexte à chaque étape. Cette amélioration permet de mieux gérer les concepts abstraits et les dépendances textuelles.
La principale caractéristique de MLA est sa capacité à ajuster dynamiquement les poids de l'attention à travers différents niveaux d'abstraction. Lors du traitement de requêtes complexes, MLA examine les données sous plusieurs angles : le sens des mots, la structure des phrases et le contexte général. Ces perspectives forment des couches distinctes qui influencent le résultat final. Pour maintenir la clarté, MLA équilibre soigneusement l'impact de chaque couche tout en restant concentré sur la tâche principale.
Les développeurs de DeepSeek ont intégré la technologie Mixture of Experts (MoE) dans le modèle. Elle contient 256 réseaux neuronaux experts pré-entraînés, chacun étant spécialisé dans des tâches différentes. Le système active 8 de ces réseaux pour chaque entrée de jeton, ce qui permet un traitement efficace des données sans augmenter les coûts de calcul.
Dans le modèle complet avec 671b paramètres, seuls 37b sont activés pour chaque jeton. Le modèle sélectionne intelligemment les paramètres les plus pertinents pour traiter chaque jeton entrant. Cette optimisation efficace permet d'économiser des ressources informatiques tout en maintenant des performances élevées.
Une caractéristique cruciale de tout chatbot à réseau neuronal est la longueur de sa fenêtre contextuelle. Llama 2 a une limite de contexte de 4 096 tokens, GPT-3.5 traite 16 284 tokens, tandis que GPT-4 et DeepSeek peuvent traiter jusqu'à 128 000 tokens (environ 100 000 mots, soit l'équivalent de 300 pages de texte dactylographié).
R - pour Reasoning (raisonnement)
DeepSeek-R1 a acquis un mécanisme de raisonnement similaire à celui de l'OpenAI o1, ce qui lui permet de traiter des tâches complexes de manière plus efficace et plus précise. Au lieu de fournir des réponses immédiates, le modèle élargit le contexte en générant un raisonnement étape par étape dans de petits paragraphes. Cette approche améliore la capacité du réseau neuronal à identifier les relations complexes entre les données, ce qui permet d'obtenir des réponses plus complètes et plus précises.
Lorsqu'il est confronté à une tâche complexe, DeepSeek utilise son mécanisme de raisonnement pour décomposer le problème en éléments et analyser chacun d'entre eux séparément. Le modèle synthétise ensuite ces résultats pour générer une réponse de l'utilisateur. Bien que cette approche semble idéale pour les réseaux neuronaux, elle s'accompagne de défis importants.
Tous les LLM modernes partagent un trait inquiétant : des hallucinations artificielles. Lorsqu'il est confronté à une question à laquelle il ne peut répondre, au lieu de reconnaître ses limites, le modèle peut générer des réponses fictives étayées par des faits inventés.
Appliquées à un réseau neuronal de raisonnement, ces hallucinations pourraient compromettre le processus de réflexion en fondant les conclusions sur des informations fictives plutôt que factuelles. Cela pourrait conduire à des conclusions erronées - un défi que les chercheurs et les développeurs de réseaux neuronaux devront relever à l'avenir.
Consommation de VRAM
Voyons comment exécuter et tester DeepSeek R1 sur un serveur dédié, en nous concentrant sur les besoins en mémoire vidéo du GPU.
| Modèle | VRAM (Mo) | Taille du modèle (Gb) |
|---|---|---|
| deepseek-r1:1.5b | 1,952 | 1.1 |
| deepseek-r1:7b | 5,604 | 4.7 |
| deepseek-r1:8b | 6,482 | 4.9 |
| deepseek-r1:14b | 10,880 | 9 |
| deepseek-r1:32b | 21,758 | 20 |
| deepseek-r1:70b | 39,284 | 43 |
| deepseek-r1:671b | 470,091 | 404 |
Les trois premières options (1.5b, 7b, 8b) sont des modèles de base qui peuvent gérer efficacement la plupart des tâches. Ces modèles fonctionnent sans problème avec n'importe quel GPU grand public doté de 6 à 8 Go de mémoire vidéo. Les versions intermédiaires (14b et 32b) sont idéales pour les tâches professionnelles mais nécessitent plus de VRAM. Les plus grands modèles (70b et 671b) nécessitent des GPU spécialisés et sont principalement utilisés pour la recherche et les applications industrielles.
Choix du serveur
Pour vous aider à choisir un serveur pour l'inférence DeepSeek, voici les configurations LeaderGPU idéales pour chaque groupe de modèles :
1.5b / 7b / 8b / 14b / 32b / 70b
Pour ce groupe, n'importe quel serveur avec les types de GPU suivants conviendra. La plupart des serveurs LeaderGPU exécuteront ces réseaux neuronaux sans problème. Les performances dépendent principalement du nombre de cœurs CUDA®. Nous recommandons les serveurs dotés de plusieurs GPU, tels que :
671b
Passons maintenant au cas le plus difficile : comment exécuter l'inférence sur un modèle dont la taille de base est de 404 Go ? Cela signifie qu'environ 470 Go de mémoire vidéo seront nécessaires. LeaderGPU propose plusieurs configurations avec les GPU suivants capables de gérer cette charge :
Les deux configurations gèrent la charge du modèle de manière efficace, en la répartissant de manière égale sur plusieurs GPU. Par exemple, voici à quoi ressemble un serveur avec 8xH100 après avoir chargé le modèle deepseek-r1:671b :
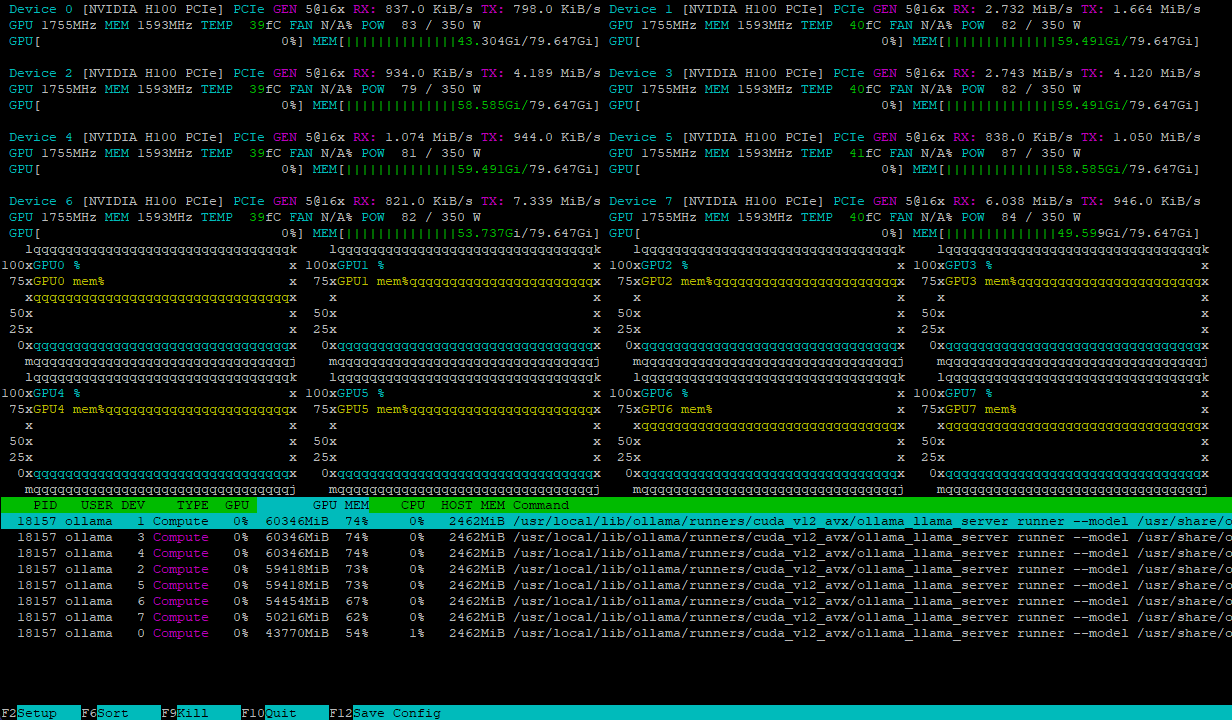
La charge de calcul s'équilibre dynamiquement entre les GPU, tandis que les interconnexions NVLink® à haut débit évitent les goulets d'étranglement dans l'échange de données, garantissant ainsi des performances maximales.
Conclusion
DeepSeek-R1 combine de nombreuses technologies innovantes telles que la prédiction multi-token, l'attention latente multi-têtes et le mélange d'experts en un seul modèle significatif. Ce logiciel open-source démontre que les LLM peuvent être développés plus efficacement avec moins de ressources informatiques. Le modèle comporte plusieurs versions, de la plus petite (1,5 milliard) à la plus grande (671 milliards), qui nécessitent du matériel spécialisé avec plusieurs GPU haut de gamme travaillant en parallèle.
En louant un serveur chez LeaderGPU pour l'inférence DeepSeek-R1, vous bénéficiez d'une large gamme de configurations, de fiabilité et de tolérance aux pannes. Notre équipe de support technique vous aidera en cas de problèmes ou de questions, tandis que l'installation automatique du système d'exploitation réduit le temps de déploiement.
Choisissez votre serveur LeaderGPU et découvrez les possibilités qui s"offrent à vous lorsque vous utilisez des modèles de réseaux neuronaux modernes. Si vous avez des questions, n'hésitez pas à les poser dans notre chat ou par e-mail.
Mis à jour: 04.01.2026
Publié: 19.02.2025




