





Triton™ Inference Server

Les exigences des entreprises peuvent varier, mais elles partagent toutes un principe fondamental : les systèmes doivent fonctionner rapidement et offrir la meilleure qualité possible. Lorsqu'il s'agit d'inférence de réseaux neuronaux, l'utilisation efficace des ressources informatiques devient cruciale. Toute sous-utilisation du GPU ou tout temps d'inactivité se traduit directement par des pertes financières.
Prenons l'exemple d'une place de marché. Ces plateformes hébergent de nombreux produits, chacun avec de multiples attributs : descriptions textuelles, spécifications techniques, catégories et contenu multimédia comme des photos et des vidéos. Tous les contenus doivent être modérés afin de maintenir des conditions équitables pour les vendeurs et d'éviter que des produits interdits ou des contenus illégaux n'apparaissent sur la plateforme.
La modération manuelle est possible, mais elle est lente et inefficace. Dans l'environnement concurrentiel actuel, les vendeurs doivent élargir rapidement leur gamme de produits : plus les articles apparaissent rapidement sur la place de marché, plus ils ont de chances d'être découverts et achetés. La modération manuelle est également coûteuse et sujette à l'erreur humaine, ce qui risque de laisser passer des contenus inappropriés.
La modération automatique à l'aide de réseaux neuronaux spécialement entraînés offre une solution. Cette approche présente de multiples avantages : elle réduit considérablement les coûts de modération tout en améliorant généralement la qualité. Les réseaux neuronaux traitent les contenus beaucoup plus rapidement que les humains, ce qui permet aux vendeurs de passer plus vite l'étape de la modération, en particulier lorsqu'ils traitent de gros volumes de produits.
Cette approche n'est pas sans poser de problèmes. La mise en œuvre de la modération automatisée nécessite le développement et l'entraînement de modèles de réseaux neuronaux, ce qui requiert à la fois du personnel qualifié et des ressources informatiques considérables. Toutefois, les avantages apparaissent rapidement après la mise en œuvre initiale. L'ajout d'un déploiement automatisé des modèles peut considérablement rationaliser les opérations en cours.
Inférence
Supposons que nous ayons compris les procédures d'apprentissage automatique. L'étape suivante consiste à déterminer comment exécuter l'inférence du modèle sur un serveur loué. Pour un modèle unique, vous choisissez généralement un outil qui fonctionne bien avec le cadre spécifique sur lequel il a été construit. Cependant, lorsqu'il s'agit de plusieurs modèles créés dans des cadres différents, deux options s'offrent à vous.
Vous pouvez soit convertir tous les modèles dans un format unique, soit choisir un outil qui prend en charge plusieurs cadres. Le serveur d'inférence Triton™ s'inscrit parfaitement dans la deuxième approche. Il prend en charge les backends suivants :
- TensorRT™
- TensorRT-LLM
- vLLM
- Python
- PyTorch (LibTorch)
- ONNX Runtime
- Tensorflow
- FIL
- DALI
En outre, vous pouvez utiliser n'importe quelle application comme backend. Par exemple, si vous avez besoin d'un post-traitement avec une application C/C++, vous pouvez l'intégrer de manière transparente.
Mise à l'échelle
Triton™ Inference Server gère efficacement les ressources informatiques sur un seul serveur en exécutant plusieurs modèles simultanément et en répartissant la charge de travail sur les GPU.
L'installation se fait par le biais d'un conteneur Docker. Les ingénieurs DevOps peuvent contrôler l'allocation des GPU au démarrage, en choisissant d'utiliser tous les GPU ou d'en limiter le nombre. Bien que le logiciel ne gère pas directement la mise à l'échelle horizontale, vous pouvez utiliser des équilibreurs de charge traditionnels comme HAproxy ou déployer des applications dans un cluster Kubernetes à cette fin.
Préparation du système
Pour configurer Triton™ sur un serveur LeaderGPU fonctionnant sous Ubuntu 22.04, commencez par mettre à jour le système à l'aide de cette commande :
sudo apt update && sudo apt -y upgradeTout d'abord, installez les pilotes NVIDIA® à l'aide du script d'installation automatique :
sudo ubuntu-drivers autoinstallRedémarrez le serveur pour appliquer les modifications :
sudo shutdown -r nowUne fois le serveur remis en ligne, installez Docker à l'aide du script d'installation suivant :
curl -sSL https://get.docker.com/ | shÉtant donné que Docker ne peut pas transmettre les GPU aux conteneurs par défaut, vous aurez besoin du NVIDIA® Container Toolkit. Ajoutez le dépôt NVIDIA® en téléchargeant et en enregistrant sa clé GPG :
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listMettez à jour le cache des paquets et installez la boîte à outils :
sudo apt update && sudo apt -y install nvidia-container-toolkitRedémarrer Docker pour activer les nouvelles capacités :
sudo systemctl restart dockerLe système d'exploitation est maintenant prêt à être utilisé.
Installation du serveur d'inférence Triton™
Téléchargez le référentiel du projet :
git clone https://github.com/triton-inference-server/serverCe référentiel contient des échantillons de réseaux neuronaux préconfigurés et un script de téléchargement de modèle. Naviguez jusqu'au répertoire examples :
cd server/docs/examplesTéléchargez les modèles en exécutant le script suivant, qui les enregistrera à l'adresse ~/server/docs/examples/model_repository:
./fetch_models.shL'architecture du serveur d'inférence Triton™ exige que les modèles soient stockés séparément. Vous pouvez les stocker localement dans n'importe quel répertoire du serveur ou sur le réseau de stockage. Lorsque vous démarrez le serveur, vous devez monter ce répertoire dans le conteneur au point de montage /models. Ce répertoire sert de dépôt pour toutes les versions des modèles.
Lancez le conteneur à l'aide de la commande suivante
sudo docker run --gpus=all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ~/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:25.01-py3 tritonserver --model-repository=/modelsVoici ce que fait chaque paramètre :
- --gpus=all spécifie que tous les GPU disponibles seront utilisés dans le serveur ;
- --rm détruit le conteneur une fois le processus terminé ou arrêté ;
- -p8000:8000 transmet le port 8000 pour recevoir les requêtes HTTP ;
- -p8001:8001 transmet le port 8001 pour recevoir les requêtes gRPC ;
- -p8002:8002 transmet le port 8002 pour demander des métriques ;
- -v ~/server/docs/examples/model_repository:/models transmet le répertoire contenant les modèles ;
- nvcr.io/nvidia/tritonserver:25.01-py3 l'adresse du conteneur du catalogue NGC™ ;
- tritonserver --model-repository=/models lance le serveur d'inférence Triton™ avec l'emplacement du référentiel de modèles à /models.
La sortie de la commande montrera tous les modèles disponibles dans le référentiel, chacun étant prêt à accepter des requêtes :
+----------------------+---------+--------+ | Model | Version | Status | +----------------------+---------+--------+ | densenet_onnx | 1 | READY | | inception_graphdef | 1 | READY | | simple | 1 | READY | | simple_dyna_sequence | 1 | READY | | simple_identity | 1 | READY | | simple_int8 | 1 | READY | | simple_sequence | 1 | READY | | simple_string | 1 | READY | +----------------------+---------+--------+
Les trois services ont été lancés avec succès sur les ports 8000, 8001 et 8002 :
I0217 08:00:34.930188 1 grpc_server.cc:2466] Started GRPCInferenceService at 0.0.0.0:8001 I0217 08:00:34.930393 1 http_server.cc:4636] Started HTTPService at 0.0.0.0:8000 I0217 08:00:34.972340 1 http_server.cc:320] Started Metrics Service at 0.0.0.0:8002
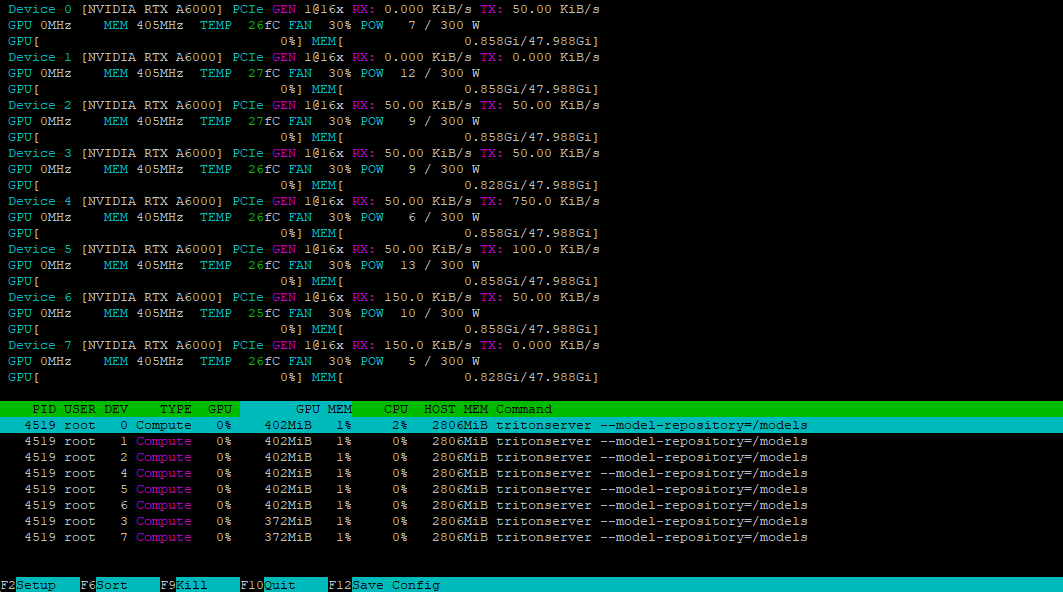
En utilisant l'utilitaire nvtop, nous pouvons vérifier que tous les GPU sont prêts à accepter la charge :
Installation du client
Pour accéder à notre serveur, nous devons générer une requête appropriée à l'aide du client inclus dans le SDK. Nous pouvons télécharger ce SDK sous la forme d'un conteneur Docker :
sudo docker pull nvcr.io/nvidia/tritonserver:25.01-py3-sdkExécutez le conteneur en mode interactif pour accéder à la console :
sudo docker run -it --gpus=all --rm --net=host nvcr.io/nvidia/tritonserver:25.01-py3-sdkTestons ceci avec le modèle DenseNet au format ONNX, en utilisant la méthode INCEPTION pour prétraiter et analyser l'image mug.jpg:
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpgLe client contactera le serveur, qui créera un lot et le traitera en utilisant les GPU disponibles du conteneur. Voici le résultat :
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.349562 (504) = COFFEE MUG
13.227461 (968) = CUP
10.424891 (505) = COFFEEPOTPréparation du dépôt
Pour que Triton™ gère correctement les modèles, vous devez préparer le référentiel d'une manière spécifique. Voici la structure du répertoire :
model_repository/
└── your_model/
├── config.pbtxt
└── 1/
└── model.*
Chaque modèle a besoin de son propre répertoire contenant un fichier de configuration config.pbtxt avec sa description. Voici un exemple :
name: "Test"
platform: "pytorch_libtorch"
max_batch_size: 8
input [
{
name: "INPUT_0"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
output [
{
name: "OUTPUT_0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]Dans cet exemple, un modèle nommé Test sera exécuté sur le backend PyTorch. Le paramètre max_batch_size définit le nombre maximal d'éléments pouvant être traités simultanément, ce qui permet d'équilibrer efficacement la charge entre les ressources. La définition de cette valeur à zéro désactive la mise en lot, ce qui fait que le modèle traite les demandes de manière séquentielle.
Le modèle accepte une entrée et produit une sortie, toutes deux utilisant le type de nombre FP32. Les paramètres doivent correspondre exactement aux exigences du modèle. Pour le traitement d'images, une spécification de dimension typique est dims: [ 3, 224, 224 ], où :
- 3 - nombre de canaux de couleur (RVB) ;
- 224 - hauteur de l'image en pixels ;
- 224 - largeur de l'image en pixels.
La sortie dims: [ 1000 ] représente un vecteur unidimensionnel de 1000 éléments, ce qui convient aux tâches de classification d'images. Pour déterminer la dimensionnalité correcte de votre modèle, consultez sa documentation. Si le fichier de configuration est incomplet, Triton™ tentera de générer automatiquement les paramètres manquants.
Lancement d'un modèle personnalisé
Lançons l'inférence du modèle DeepSeek-R1 distillé dont nous avons parlé précédemment. Tout d'abord, nous allons créer la structure de répertoire nécessaire :
mkdir ~/model_repository && mkdir ~/model_repository/deepseek && mkdir ~/model_repository/deepseek/1Naviguez jusqu'au répertoire du modèle :
cd ~/model_repository/deepseekCréer un fichier de configuration config.pbtxt:
nano config.pbtxtCollez les éléments suivants :
# Copyright 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of NVIDIA CORPORATION nor the names of its
# contributors may be used to endorse or promote products derived
# from this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
# PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
# CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
# EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
# PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
# PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
# OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# Note: You do not need to change any fields in this configuration.
backend: "vllm"
# The usage of device is deferred to the vLLM engine
instance_group [
{
count: 1
kind: KIND_MODEL
}
]Enregistrez le fichier en appuyant sur Ctrl + O, puis l'éditeur avec Ctrl + X. Naviguez jusqu'au répertoire 1:
cd 1Créer un fichier de configuration du modèle model.json avec les paramètres suivants :
{
"model":"deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"disable_log_requests": true,
"gpu_memory_utilization": 0.9,
"enforce_eager": true
}Notez que la valeur de gpu_memory_utilization varie selon le GPU et doit être déterminée expérimentalement. Pour ce guide, nous utiliserons 0.9. La structure de votre répertoire à l'intérieur de ~/model_repository devrait maintenant ressembler à ceci :
└── deepseek
├── 1
│ └── model.json
└── config.pbtxt
Définissez la variable LOCAL_MODEL_REPOSITORY pour plus de commodité :
LOCAL_MODEL_REPOSITORY=~/model_repository/Démarrez le serveur d'inférence avec cette commande :
sudo docker run --rm -it --net host --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 tritonserver --model-repository=model_repository/Voici ce que fait chaque paramètre :
- --rm supprime automatiquement le conteneur après l'avoir arrêté ;
- -it exécute le conteneur en mode interactif avec une sortie terminal ;
- --net L'hôte utilise la pile réseau de l'hôte au lieu de l'isolation du conteneur ;
- --shm-size=2g fixe la mémoire partagée à 2 Go ;
- --ulimit memlock=-1 supprime la limite de verrouillage de la mémoire ;
- --ulimit stack=67108864 fixe la taille de la pile à 64 Mo ;
- --gpus all autorise l'accès à tous les GPU du serveur ;
- -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository monte le répertoire du modèle local dans le conteneur ;
- nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 spécifie le conteneur avec le support du backend vLLM ;
- tritonserver --model-repository=model_repository/ lance le serveur d'inférence Triton™ avec l'emplacement du référentiel de modèles à model_repository.
Testez le serveur en envoyant une requête avec curl, en utilisant une simple invite et une limite de réponse de 4096 jetons :
curl -X POST localhost:8000/v2/models/deepseek/generate -d '{"text_input": "Tell me about the Netherlands?", "max_tokens": 4096}'Le serveur reçoit et traite la demande avec succès.
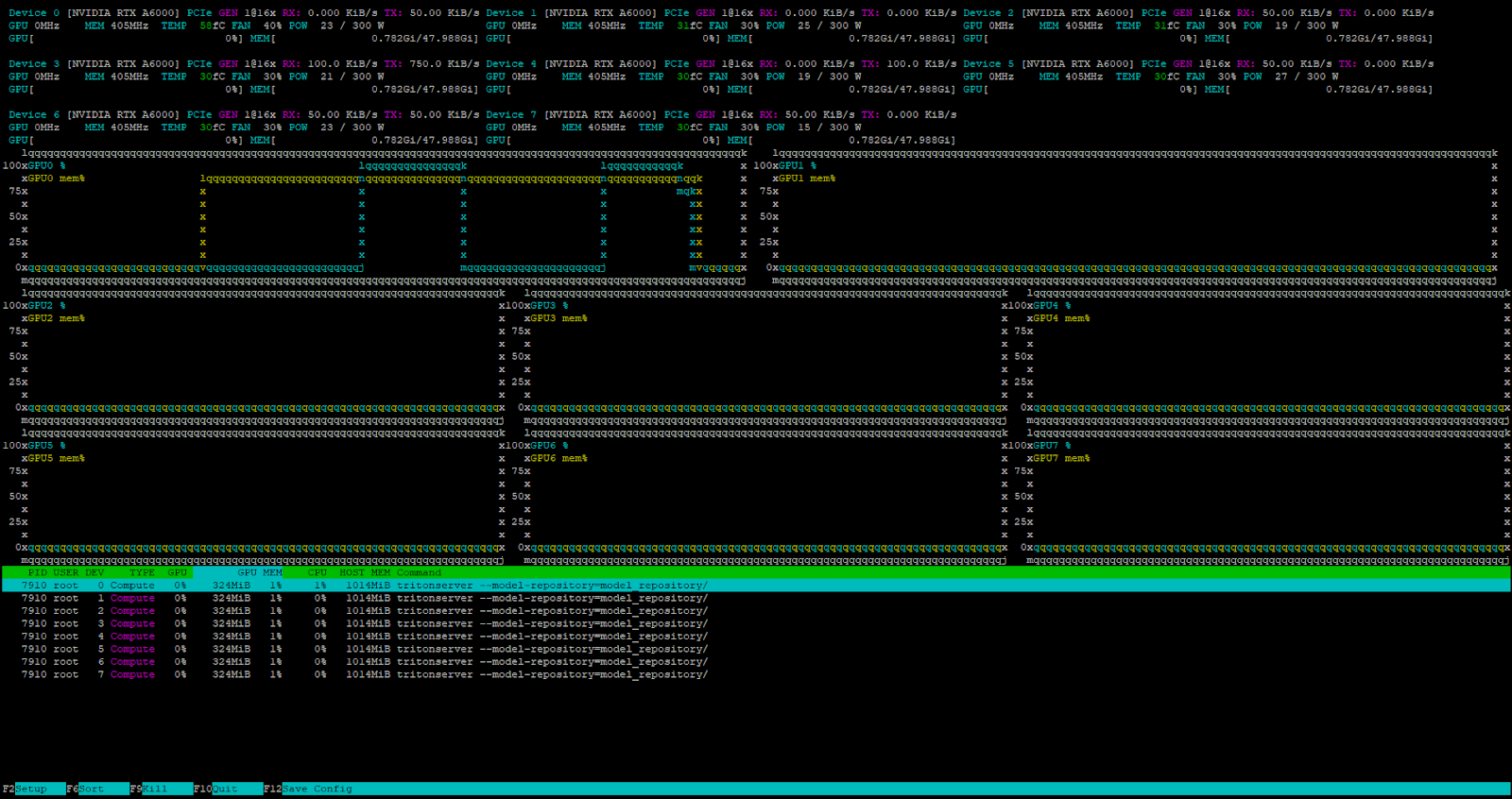
Le planificateur de tâches interne de Triton™ traite toutes les demandes entrantes lorsque le serveur est en charge.
Conclusion
Le serveur d'inférence Triton™ excelle dans le déploiement de modèles d'apprentissage automatique en production en distribuant efficacement les demandes sur les GPU disponibles. Cela permet de maximiser l'utilisation des ressources serveur louées et de réduire les coûts de l'infrastructure informatique. Le logiciel fonctionne avec différents backends, notamment vLLM pour les modèles de langage de grande taille.
Comme il s'installe sous forme de conteneur Docker, vous pouvez facilement l'intégrer dans n'importe quel pipeline CI/CD moderne. Essayez-le vous-même en louant un serveur auprès de LeaderGPU.
Mis à jour: 04.01.2026
Publié: 26.02.2025




