





Qwen3-Coder : un paradigme brisé

Nous avons l'habitude de penser que les modèles open-source sont toujours moins bons que leurs homologues commerciaux en termes de qualité. Il peut sembler qu'ils soient développés exclusivement par des passionnés qui n'ont pas les moyens d'investir des sommes considérables dans la création d'ensembles de données de haute qualité et dans l'entraînement de modèles sur des dizaines de milliers de GPU modernes.
Il en va tout autrement lorsque de grandes entreprises comme OpenAI, Anthropic ou Meta s'attellent à la tâche. Elles disposent non seulement des ressources nécessaires, mais aussi des meilleurs spécialistes mondiaux des réseaux neuronaux. Malheureusement, les modèles qu'elles créent, en particulier les dernières versions, sont fermés. Les développeurs expliquent cela par les risques d'une utilisation incontrôlée et la nécessité d'assurer la sécurité de l'IA.
D'une part, leur raisonnement est compréhensible : de nombreuses questions éthiques restent en suspens et la nature même des modèles de réseaux neuronaux ne permet qu'une influence indirecte sur le résultat final. D'autre part, le fait de garder les modèles fermés et de n'en offrir l'accès que par l'intermédiaire de leur propre API est également un modèle commercial solide.
Cependant, toutes les entreprises ne se comportent pas de la sorte. Par exemple, la société française Mistral AI propose à la fois des modèles commerciaux et des modèles libres, permettant aux chercheurs et aux passionnés de les utiliser dans leurs projets. Mais il convient d'accorder une attention particulière aux réalisations des entreprises chinoises, dont la plupart construisent des modèles à poids ouvert et à code source ouvert capables de concurrencer sérieusement les solutions propriétaires.
DeepSeek, Qwen3 et Kimi K2
La première avancée majeure a été réalisée avec DeepSeek-V3. Ce modèle de langage multimodal de DeepSeek AI a été développé en utilisant l'approche du mélange d'experts (MoE) et comprend 671 milliards de paramètres, dont 37 milliards de paramètres les plus pertinents activés pour chaque token. Plus important encore, tous ses composants (poids du modèle, code d'inférence et pipelines d'entraînement) ont été rendus publics.
Cela en a fait instantanément l'un des LLM les plus attrayants pour les développeurs d'applications d'IA et les chercheurs. DeepSeek-R1, le premier modèle de raisonnement en libre accès, a ensuite fait la une des journaux. Le jour de sa sortie, il a fait trembler le marché boursier américain après que ses développeurs ont affirmé que la formation d'un modèle aussi avancé n'avait coûté que 6 millions de dollars.
Si le battage médiatique autour de DeepSeek s'est finalement calmé, les versions suivantes n'en ont pas moins été importantes pour l'industrie mondiale de l'IA. Il s'agit bien sûr de Qwen 3. Nous avons abordé ses caractéristiques en détail dans notre analyse des Nouveautés de Qwen 3, et nous ne nous attarderons donc pas sur ce point ici. Peu de temps après, un autre joueur est apparu : Kimi K2 de Moonshot AI.
Avec son architecture MoE, ses paramètres 1T (32B activés par jeton) et son code open-source, Kimi K2 a rapidement attiré l'attention de la communauté. Plutôt que de se concentrer sur le raisonnement, Moonshot AI visait des performances de pointe en mathématiques, en programmation et en connaissances interdisciplinaires approfondies.
L'atout de Kimi K2 était son optimisation pour l'intégration dans des agents d'intelligence artificielle. Ce réseau a été littéralement conçu pour exploiter pleinement tous les outils disponibles. Il excelle dans les tâches qui requièrent non seulement l'écriture de codes, mais aussi des tests itératifs à chaque étape du développement. Cependant, il présente également des faiblesses, que nous aborderons plus loin.
Kimi K2 est un grand modèle de langage dans tous les sens du terme. L'exécution de la version complète nécessite ~2 TB de VRAM (FP8 : ~1 TB). Pour des raisons évidentes, ce n'est pas quelque chose que vous pouvez faire chez vous, et même de nombreux serveurs GPU ne le supporteront pas. Le modèle nécessite au moins 8 accélérateurs NVIDIA® H200. Les versions quantifiées peuvent aider, mais au prix d'une baisse sensible de la précision.
Qwen3-Codeur
Voyant le succès de Moonshot AI, Alibaba a développé son propre modèle semblable à Kimi K2, mais avec des avantages significatifs dont nous parlerons bientôt. Au départ, il a été publié en deux versions :
- Qwen3-Coder-480B-A35B-Instruct (~250 Go VRAM)
- Qwen3-Coder-480B-A35B-Instruct-FP8 (~120 Go de VRAM)
Quelques jours plus tard, des modèles plus petits sans le mécanisme de raisonnement sont apparus, nécessitant beaucoup moins de VRAM :
- Qwen3-Coder-30B-A3B-Instruct (~32 Go de VRAM)
- Qwen3-Coder-30B-A3B-Instruct-FP8 (~18 Go VRAM)
Qwen3-Coder a été conçu pour être intégré à des outils de développement. Il comprend un analyseur spécial pour les appels de fonction (qwen3coder_tool_parser.py, analogue à l'appel de fonction d'OpenAI). Parallèlement au modèle, un utilitaire de console a été publié, capable d'effectuer des tâches allant de la compilation de code à l'interrogation d'une base de connaissances. Cette idée n'est pas nouvelle, il s'agit essentiellement d'une extension fortement retravaillée de l'application de code Gemini d'Anthropic.
Le modèle est compatible avec l'API OpenAI, ce qui permet de le déployer localement ou sur un serveur distant et de le connecter à la plupart des systèmes qui supportent cette API. Cela inclut à la fois les applications clientes prêtes à l'emploi et les bibliothèques d'apprentissage automatique. Cela le rend viable non seulement pour le segment B2C mais aussi pour le segment B2B, offrant un remplacement transparent du produit d'OpenAI sans aucune modification de la logique de l'application.
L'une de ses caractéristiques les plus demandées est l'extension de la longueur du contexte. Par défaut, il prend en charge 256k jetons mais peut être porté à 1M à l'aide du mécanisme YaRN (Yet another RoPe extensioN). Les LLM modernes sont généralement formés sur des ensembles de données courts (2k-8k tokens), et de grandes longueurs de contexte peuvent leur faire perdre la trace du contenu antérieur.
YaRN est une "astuce" élégante qui fait croire au modèle qu'il travaille avec ses séquences courtes habituelles alors qu'il traite en réalité des séquences beaucoup plus longues. L'idée clé est d'"étirer" ou de "dilater" l'espace positionnel tout en préservant la structure mathématique attendue par le modèle. Cela permet de traiter efficacement des séquences de plusieurs dizaines de milliers de tokens sans réentraînement ni mémoire supplémentaire requise par les méthodes traditionnelles d'extension du contexte.
Télécharger et exécuter Inference
Assurez-vous d'avoir installé CUDA® au préalable, soit en utilisant les instructions officielles de NVIDIA®, soit en consultant le guide Installer la boîte à outils CUDA® sous Linux. Vérifiez que vous disposez du compilateur requis :
nvcc --versionRésultat attendu :
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2024 NVIDIA Corporation Built on Tue_Feb_27_16:19:38_PST_2024 Cuda compilation tools, release 12.4, V12.4.99 Build cuda_12.4.r12.4/compiler.33961263_0
Si vous obtenez :
Command 'nvcc' not found, but can be installed with: sudo apt install nvidia-cuda-toolkit
vous devez ajouter les binaires CUDA® au $PATH de votre système.
export PATH=/usr/local/cuda-12.4/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATHIl s'agit d'une solution temporaire. Pour une solution permanente, éditez ~/.bashrc et ajoutez les deux mêmes lignes à la fin.
Maintenant, préparez votre système à gérer des environnements virtuels. Vous pouvez utiliser le logiciel intégré venv de Python ou le logiciel plus avancé Miniforge. En supposant que Miniforge est installé :
conda create -n venv python=3.10conda activate venvInstallez PyTorch avec le support CUDA® correspondant à votre système :
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124Installez ensuite les bibliothèques essentielles :
- Transformers - La bibliothèque de modèles principale de Hugging Face
- Accelerate - permet l'inférence multi-GPU
- HuggingFace Hub - pour le téléchargement de modèles et d'ensembles de données
- Safetensors - format de poids de modèle sûr
- vLLM - bibliothèque d'inférence recommandée pour Qwen
pip install transformers accelerate huggingface_hub safetensors vllmTélécharger le modèle :
hf download Qwen/Qwen3-Coder-30B-A3B-Instruct --local-dir ./Qwen3-30BExécuter l'inférence avec le parallélisme tensoriel (répartir les couches tensorielles sur les GPU, par exemple 8) :
python -m vllm.entrypoints.openai.api_server \
--model /home/usergpu/Qwen3-30B \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.9 \
--dtype auto \
--host 0.0.0.0 \
--port 8000Ceci lance le serveur vLLM OpenAI API.
Test et intégration
cURL
Installer jq pour l'impression de JSON :
sudo apt -y install jqTester le serveur :
curl -s http://127.0.0.1:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/home/usergpu/Qwen3-30B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello! What can you do?"}
],
"max_tokens": 180
}' | jq -r '.choices[0].message.content'VSCode
Pour intégrer Visual Studio Code, installez l'extension Continue et ajoutez-la à config.yaml:
- name: Qwen3-Coder 30B
provider: openai
apiBase: http://[server_IP_address]:8000/v1
apiKey: none
model: /home/usergpu/Qwen3-30B
roles:
- chat
- edit
- apply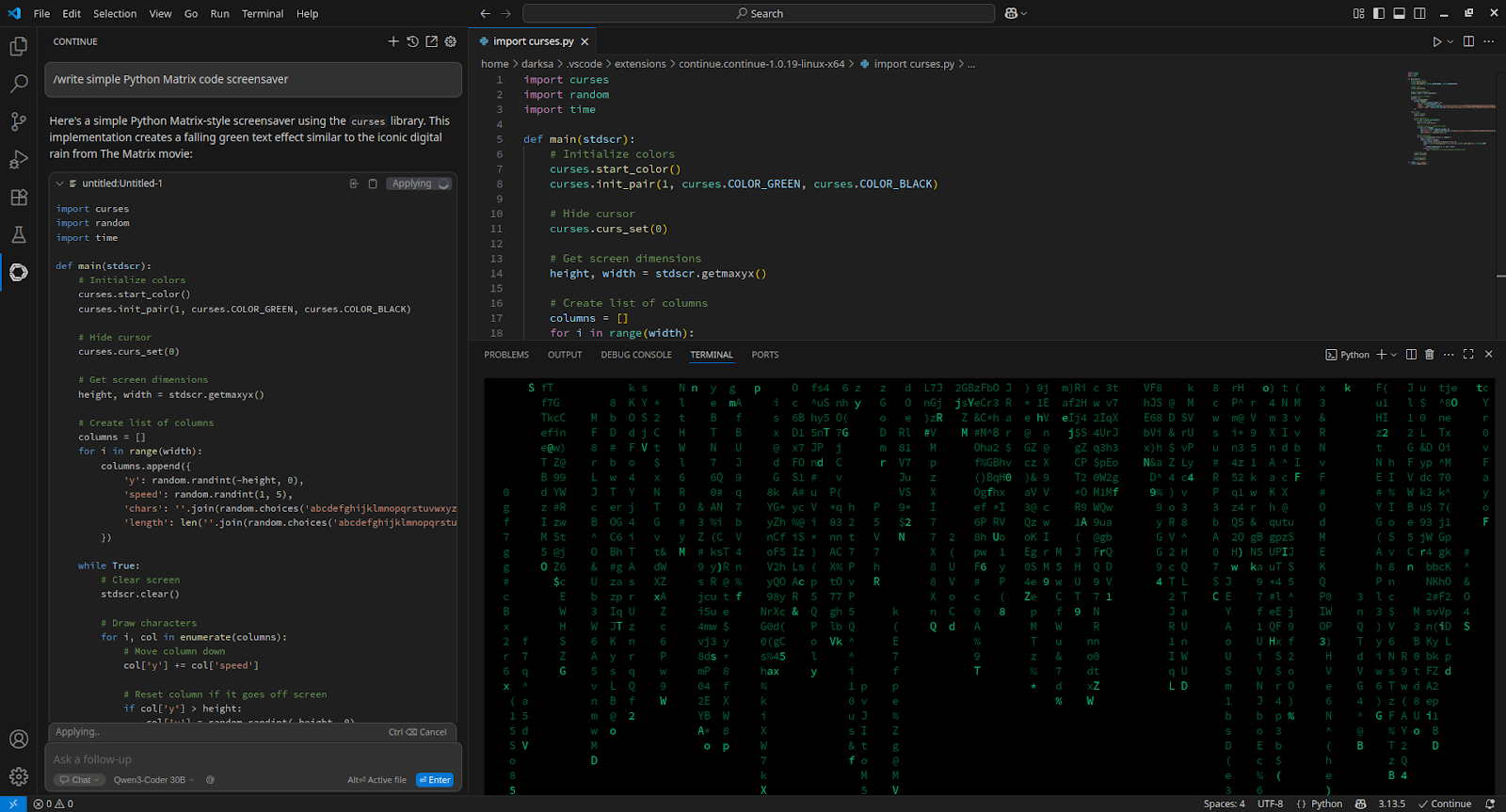
Qwen-Agent
Pour une installation basée sur l'interface graphique avec Qwen-Agent (y compris RAG, MCP et l'interpréteur de code) :
pip install -U "qwen-agent[gui,rag,code_interpreter,mcp]"Ouvrez l'éditeur nano :
nano script.pyExemple de script Python pour lancer Qwen-Agent avec une WebUI Gradio :
from qwen_agent.agents import Assistant
from qwen_agent.gui import WebUI
llm_cfg = {
'model': '/home/usergpu/Qwen3-30B',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
'generate_cfg': {'top_p': 0.8},
}
tools = ['code_interpreter']
bot = Assistant(
llm=llm_cfg,
system_message="You are a helpful coding assistant.",
function_list=tools
)
WebUI(bot).run()Exécuter le script :
python script.pyLe serveur sera disponible à l'adresse suivante : http://127.0.0.1:7860
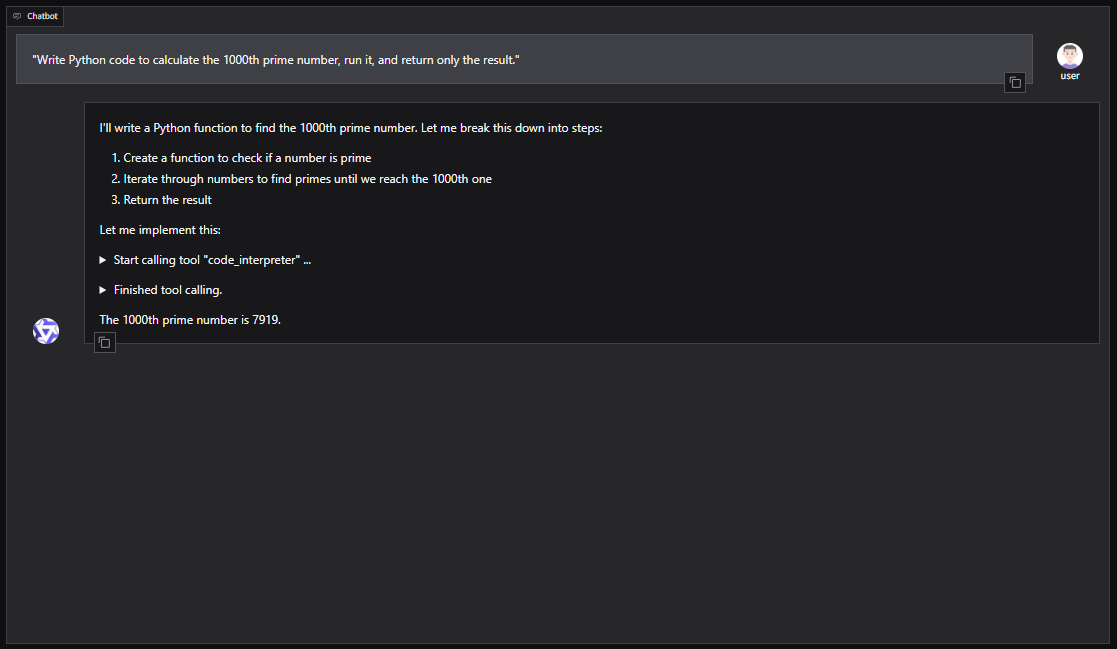
Vous pouvez également intégrer Qwen3-Coder dans des cadres d'agents tels que CrewAI pour automatiser des tâches complexes à l'aide d'outils tels que la recherche sur le web ou la mémoire de base de données vectorielles.
Voir aussi :
Mis à jour: 04.01.2026
Publié: 12.08.2025




