





Comment fonctionne Ollama ?

Ollama est un outil permettant d'exécuter localement de grands modèles de réseaux neuronaux. L'utilisation des services publics est souvent perçue par les entreprises comme un risque potentiel de fuite de données confidentielles et sensibles. Par conséquent, le déploiement de LLM sur un serveur contrôlé vous permet de gérer de manière indépendante les données qui y sont placées tout en utilisant les forces de LLM.
Cela permet également d'éviter la situation désagréable du verrouillage du fournisseur, où tout service public peut unilatéralement cesser de fournir des services. Bien entendu, l'objectif initial est de permettre l'utilisation de réseaux neuronaux génératifs dans des lieux où l'accès à l'internet est absent ou difficile (par exemple, dans un avion).
L'idée était de simplifier le lancement, le contrôle et le réglage fin des LLM. Au lieu d'instructions complexes en plusieurs étapes, Ollama vous permet d'exécuter une simple commande et de recevoir le résultat final après un certain temps. Il sera présenté simultanément sous la forme d'un modèle de réseau neuronal local, avec lequel vous pouvez communiquer à l'aide d'une interface web et d'une API pour une intégration facile dans d'autres applications.
Pour de nombreux développeurs, cet outil est devenu très utile, car dans la plupart des cas, il était possible d'intégrer Ollama à l'IDE utilisé et de recevoir des recommandations ou du code prêt à l'emploi écrit directement pendant que l'on travaillait sur l'application.
À l'origine, Ollama était destiné uniquement aux ordinateurs équipés du système d'exploitation macOS, mais il a ensuite été porté sur Linux et Windows. Une version spéciale a également été publiée pour travailler dans des environnements conteneurisés tels que Docker. Actuellement, il fonctionne aussi bien sur les ordinateurs de bureau que sur les serveurs dédiés dotés d'un GPU. Ollama permet de passer d'un modèle à l'autre dès la sortie de la boîte et de maximiser toutes les ressources disponibles. Bien entendu, ces modèles ne sont pas aussi performants sur un ordinateur de bureau classique, mais ils fonctionnent de manière tout à fait adéquate.
Comment installer Ollama
Ollama peut être installé de deux manières : sans utiliser la conteneurisation, en utilisant un script d'installation, et en tant que conteneur Docker prêt à l'emploi. La première méthode facilite la gestion des composants du système et des modèles installés, mais est moins tolérante aux pannes. La seconde méthode est plus tolérante aux pannes, mais son utilisation nécessite de prendre en compte tous les aspects inhérents aux conteneurs : une gestion un peu plus complexe et une approche différente du stockage des données.
Quelle que soit la méthode choisie, plusieurs étapes supplémentaires sont nécessaires pour préparer le système d'exploitation.
Les prérequis
Mettre à jour le dépôt de cache des paquets et les paquets installés :
sudo apt update && sudo apt -y upgradeInstaller tous les pilotes GPU nécessaires à l'aide de la fonction d'installation automatique :
sudo ubuntu-drivers autoinstallRedémarrer le serveur :
sudo shutdown -r nowInstallation par script
Le script suivant détecte l'architecture du système d'exploitation actuel et installe la version appropriée d'Ollama :
curl -fsSL https://ollama.com/install.sh | shPendant l'opération, le script créera un utilisateur ollama distinct, sous lequel le démon correspondant sera lancé. Incidemment, le même script fonctionne bien dans WSL2, permettant l'installation de la version Linux d'Ollama sur Windows Server.
Installation via Docker
Il existe plusieurs méthodes pour installer Docker Engine sur un serveur. La plus simple consiste à utiliser un script spécifique qui installe la version actuelle de Docker. Cette approche est efficace pour Ubuntu Linux, de la version 20.04 (LTS) à la dernière version, Ubuntu 24.04 (LTS) :
curl -sSL https://get.docker.com/ | shPour que les conteneurs Docker interagissent correctement avec le GPU, une boîte à outils supplémentaire doit être installée. Comme il n'est pas disponible dans les dépôts de base d'Ubuntu, vous devez d'abord ajouter un dépôt tiers à l'aide de la commande suivante :
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listMettre à jour le dépôt de cache de paquets :
sudo apt updateEt installez le paquet nvidia-container-toolkit:
sudo apt install nvidia-container-toolkitN'oubliez pas de redémarrer le daemon docker via systemctl :
sudo systemctl restart dockerIl est temps de télécharger et d'exécuter Ollama avec l'interface web Open-WebUI :
sudo docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaOuvrez le navigateur web et naviguez vers http://[server-ip]:3000:
Télécharger et exécuter les modèles
En ligne de commande
Il suffit d'exécuter la commande suivante :
ollama run llama3Via l'interface WebUI
Ouvrez Settings > Models, tapez le nom du modèle nécessaire, par exemple, llama3 et cliquez sur le bouton avec le symbole de téléchargement :

Le modèle sera téléchargé et installé automatiquement. Une fois le téléchargement terminé, fermez la fenêtre de configuration et sélectionnez le modèle téléchargé. Vous pourrez alors entamer un dialogue avec lui :

Intégration du VSCode
Si vous avez installé Ollama en utilisant le script d'installation, vous pouvez lancer n'importe quel modèle supporté presque instantanément. Dans l'exemple suivant, nous lancerons le modèle par défaut attendu par l'extension Ollama Autocoder (openhermes2.5-mistral:7b-q4_K_M) :
ollama run openhermes2.5-mistral:7b-q4_K_MPar défaut, Ollama permet de travailler à travers une API, autorisant uniquement les connexions à partir de l'hôte local. Par conséquent, avant d'installer et d'utiliser l'extension pour Visual Studio Code, une redirection de port est nécessaire. Plus précisément, vous devez rediriger le port distant 11434 vers votre ordinateur local. Vous trouverez un exemple de cette procédure dans notre article sur Easy Diffusion WebUI.
Tapez Ollama Autocoder dans un champ de recherche, puis cliquez sur Install:
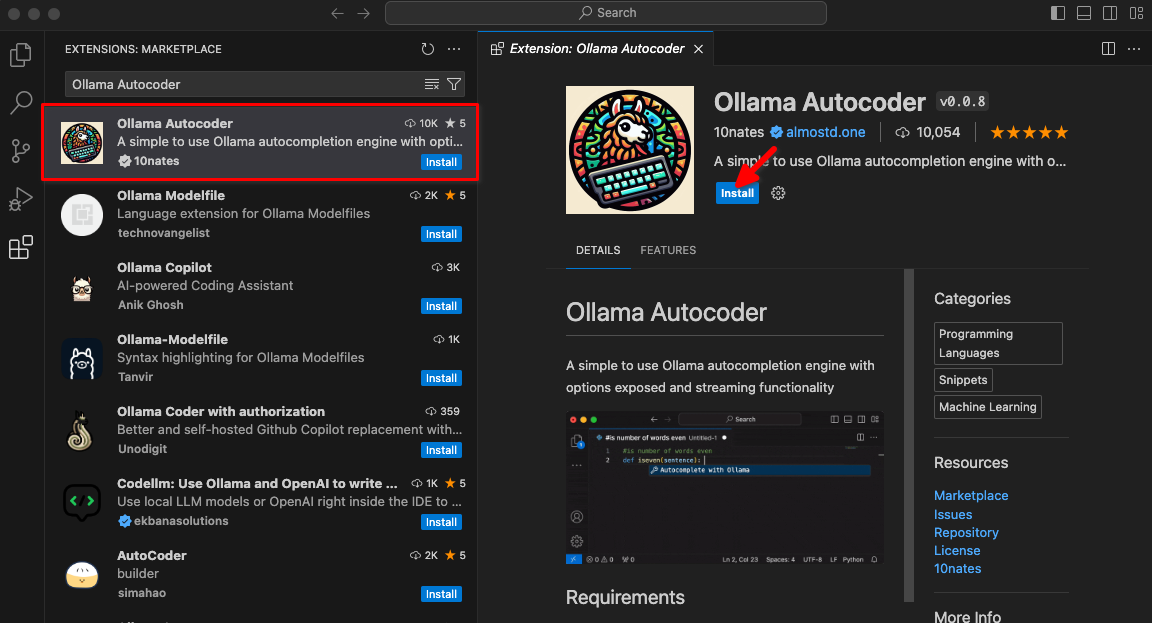
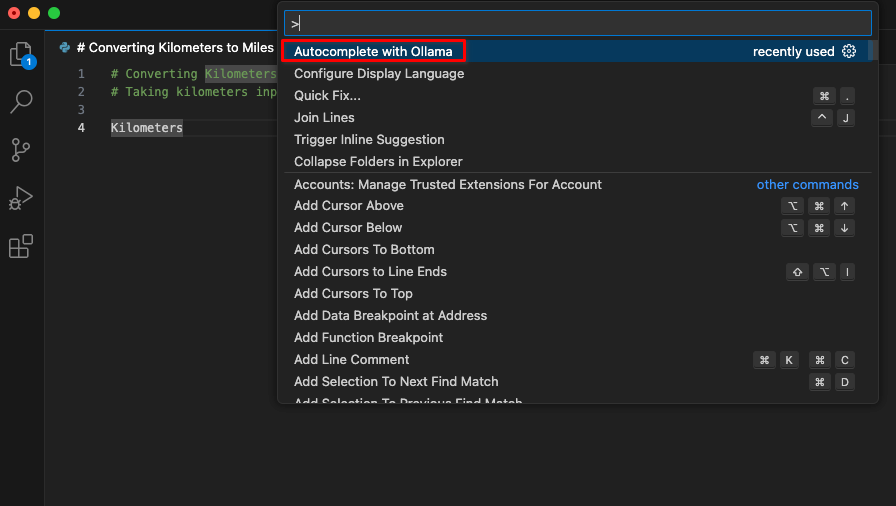
Après l'installation de l'extension, un nouvel élément intitulé Autocomplete with Ollama sera disponible dans la palette de commandes. Commencez à coder et lancez cette commande.
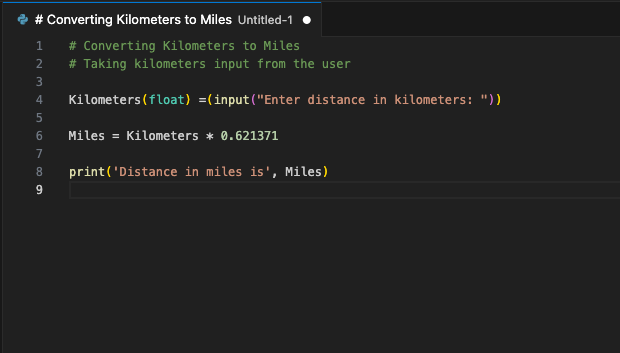
L'extension se connectera au serveur LeaderGPU en utilisant la redirection de port et dans quelques secondes, le code généré s'affichera sur votre écran :
Vous pouvez assigner cette commande à un raccourci clavier. Vous pouvez assigner cette commande à un raccourci clavier. Utilisez-la chaque fois que vous souhaitez compléter votre code avec un fragment généré. Ce n'est qu'un exemple des extensions VSCode disponibles. Le principe du transfert de port d'un serveur distant vers un ordinateur local vous permet de mettre en place un seul serveur avec un LLM en cours d'exécution pour toute une équipe de développeurs. Cette garantie empêche les entreprises tierces ou les pirates d'utiliser le code envoyé.
Voir aussi:
Mis à jour: 04.01.2026
Publié: 20.01.2025




