





Votre propre LLaMa 2 sous Linux

Étape 1. Préparer le système d'exploitation
Mise à jour du cache et des paquets
Mettons à jour le cache des paquets et mettons à niveau votre système d'exploitation avant de commencer à configurer LLaMa 2. Veuillez noter que pour ce guide, nous utilisons Ubuntu 22.04 LTS comme système d'exploitation :
sudo apt update && sudo apt -y upgradeNous devons également ajouter Python Installer Packages (PIP), s'il n'est pas déjà présent dans le système :
sudo apt install python3-pipInstaller les pilotes NVIDIA®
Vous pouvez utiliser l'utilitaire automatisé qui est inclus par défaut dans les distributions Ubuntu :
sudo ubuntu-drivers autoinstallVous pouvez également installer les pilotes NVIDIA® manuellement à l'aide de notre guide étape par étape. N'oubliez pas de redémarrer le serveur :
sudo shutdown -r nowÉtape 2. Obtenir des modèles de MetaAI
Demande officielle
Ouvrez l'adresse suivante dans votre navigateur : https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Remplissez tous les champs nécessaires, lisez les conditions d'utilisation et cliquez sur le bouton Agree and Continue. Après quelques minutes (heures, jours), vous recevrez une URL de téléchargement spéciale, qui vous autorise à télécharger des modèles pendant une période de 24 heures.
Cloner le dépôt
Avant de télécharger, vérifiez l'espace de stockage disponible :
df -hFilesystem Size Used Avail Use% Mounted on tmpfs 38G 3.3M 38G 1% /run /dev/sda2 99G 24G 70G 26% / tmpfs 189G 0 189G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/nvme0n1 1.8T 26G 1.7T 2% /mnt/fastdisk tmpfs 38G 8.0K 38G 1% /run/user/1000
Si vous avez des disques locaux non montés, veuillez suivre les instructions de la section Partitionnement des disques sous Linux. Ceci est important car les modèles téléchargés peuvent être très volumineux et vous devez planifier leur emplacement de stockage à l'avance. Dans cet exemple, nous avons un disque SSD local monté dans le répertoire /mnt/fastdisk. Ouvrons-le :
cd /mnt/fastdiskCréer une copie du référentiel LLaMa original :
git clone https://github.com/facebookresearch/llamaSi vous rencontrez une erreur de permission, accordez simplement les permissions à l'utilisateurergpu :
sudo chown -R usergpu:usergpu /mnt/fastdisk/Téléchargement par script
Ouvrez le répertoire téléchargé :
cd llamaExécuter le script :
./download.shPasser l'URL fournie par MetaAI et sélectionner tous les modèles nécessaires. Nous recommandons de télécharger tous les modèles disponibles afin d'éviter de redemander l'autorisation. Toutefois, si vous avez besoin d'un modèle spécifique, ne téléchargez que celui-ci.
Test rapide via l'application d'exemple
Pour commencer, nous pouvons vérifier s'il manque des composants. Si des bibliothèques ou des applications sont manquantes, le gestionnaire de paquets les installera automatiquement :
pip install -e .L'étape suivante consiste à ajouter de nouveaux binaires à PATH :
export PATH=/home/usergpu/.local/bin:$PATHExécutez l'exemple de démonstration :
torchrun --nproc_per_node 1 /mnt/fastdisk/llama/example_chat_completion.py --ckpt_dir /mnt/fastdisk/llama-2-7b-chat/ --tokenizer_path /mnt/fastdisk/llama/tokenizer.model --max_seq_len 512 --max_batch_size 6L'application créera un processus de calcul sur le premier GPU et simulera un dialogue simple avec des demandes typiques, en générant des réponses à l'aide de LLaMa 2.
Étape 3. Obtenir llama.cpp
LLaMa C++ est un projet créé par le physicien bulgare et développeur de logiciels Georgi Gerganov. Il comporte de nombreux utilitaires qui facilitent l'utilisation de ce modèle de réseau neuronal. Toutes les parties de llama.cpp sont des logiciels libres et sont distribuées sous la licence MIT.
Cloner le dépôt
Ouvrez le répertoire de travail sur le SSD :
cd /mnt/fastdiskCloner le référentiel du projet :
git clone https://github.com/ggerganov/llama.cpp.gitCompiler les applications
Ouvrez le répertoire cloné :
cd llama.cppLancez le processus de compilation à l'aide de la commande suivante :
makeÉtape 4. Obtenir text-generation-webui
Cloner le dépôt
Ouvrez le répertoire de travail sur le SSD :
cd /mnt/fastdiskCloner le référentiel du projet :
git clone https://github.com/oobabooga/text-generation-webui.gitInstaller les exigences
Ouvrir le répertoire téléchargé :
cd text-generation-webuiVérifier et installer tous les composants manquants :
pip install -r requirements.txtÉtape 5. Convertir PTH en GGUF
Formats courants
PTH (Python TorcH) - Un format consolidé. Il s'agit essentiellement d'une archive ZIP standard avec un dictionnaire d'états PyTorch sérialisé. Cependant, ce format a des alternatives plus rapides telles que GGML et GGUF.
GGML (Georgi Gerganov’s Machine Learning) - Il s'agit d'un format de fichier créé par Georgi Gerganov, l'auteur de llama.cpp. Il est basé sur une bibliothèque du même nom, écrite en C++, qui a considérablement augmenté les performances des grands modèles de langage. Il a été remplacé par le format moderne GGUF.
GGUF (Georgi Gerganov’s Unified Format) - Il s'agit d'un format de fichier largement utilisé pour les LLM, pris en charge par diverses applications. Il offre une flexibilité, une évolutivité et une compatibilité accrues pour la plupart des cas d'utilisation.
llama.cpp convert.py script
Modifie les paramètres du modèle avant de le convertir :
nano /mnt/fastdisk/llama-2-7b-chat/params.jsonCorrigez "vocab_size": -1 en "vocab_size": 32000. Sauvegardez le fichier et quittez. Ouvrez ensuite le répertoire llama.cpp :
cd /mnt/fastdisk/llama.cppExécutez le script qui convertira le modèle au format GGUF :
python3 convert.py /mnt/fastdisk/llama-2-7b-chat/ --vocab-dir /mnt/fastdisk/llamaSi toutes les étapes précédentes sont correctes, vous recevrez un message comme celui-ci :
Wrote /mnt/fastdisk/llama-2-7b-chat/ggml-model-f16.gguf
Étape 6. WebUI
Comment démarrer l'interface WebUI
Ouvrez le répertoire :
cd /mnt/fastdisk/text-generation-webui/Exécuter le script de démarrage avec quelques paramètres utiles :
- --model-dir indique le chemin d'accès correct aux modèles
- --share crée un lien public temporaire (si vous ne voulez pas transmettre un port via SSH)
- --gradio-auth ajoute une autorisation avec un login et un mot de passe (remplacez user:password par le vôtre)
./start_linux.sh --model-dir /mnt/fastdisk/llama-2-7b-chat/ --share --gradio-auth user:passwordAprès un lancement réussi, vous recevrez un lien local et un lien de partage temporaire pour l'accès :
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://e9a61c21593a7b251f.gradio.live
Ce lien de partage expire dans 72 heures.
Charger le modèle
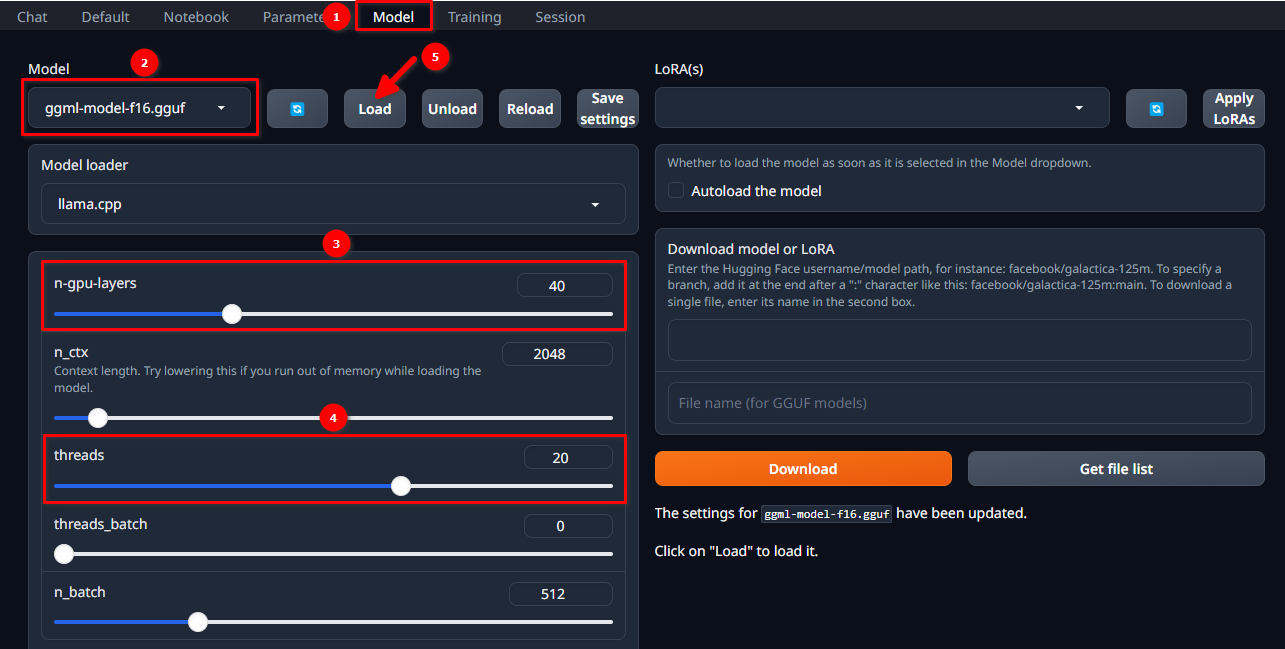
Autorisez-vous dans l'interface WebUI en utilisant le nom d'utilisateur et le mot de passe sélectionnés et suivez ces 5 étapes simples :
- Naviguez jusqu'à l'onglet Model.
- Sélectionnez ggml-model-f16.gguf dans le menu déroulant.
- Choisissez le nombre de couches que vous souhaitez calculer sur le GPU (n-gpu-layers).
- Choisissez le nombre de threads que vous souhaitez démarrer (threads).
- Cliquez sur le bouton Load.
Démarrer le dialogue
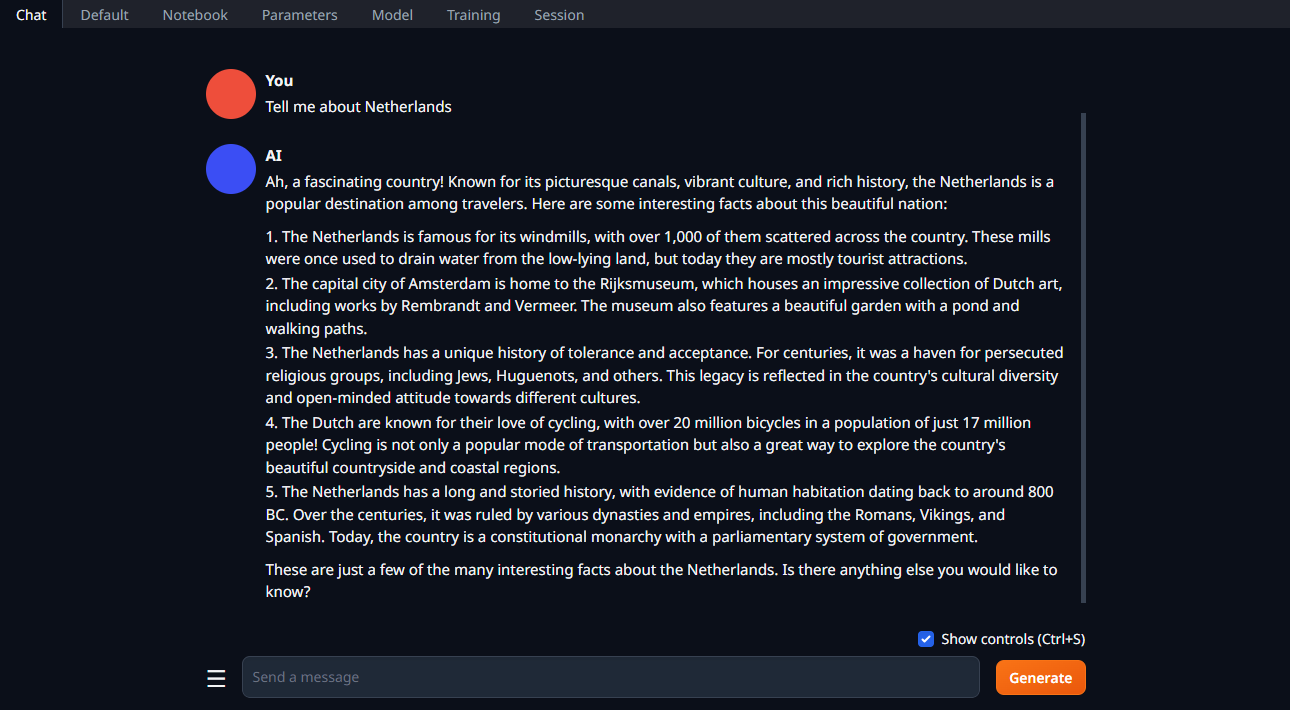
Changez l'onglet en Chat, tapez votre invite et cliquez sur Generate:
Voir aussi:
Mis à jour: 04.01.2026
Publié: 20.01.2025




