





Qwen 2 vs Llama 3

Les grands modèles de langage (LLM) ont eu un impact considérable sur notre vie. Malgré la compréhension de leur structure interne, ces modèles restent un point d'attention pour les scientifiques qui les comparent souvent à une "boîte noire". Le résultat final dépend non seulement de la conception du LLM, mais aussi de son entraînement et des données utilisées pour l'entraînement.
Alors que les scientifiques trouvent des opportunités de recherche, les utilisateurs finaux sont principalement intéressés par deux choses : la vitesse et la qualité. Ces critères jouent un rôle crucial dans le processus de sélection. Pour comparer avec précision deux LLM, de nombreux facteurs apparemment sans rapport doivent être normalisés.
L'équipement utilisé pour les interférences et l'environnement logiciel, y compris le système d'exploitation, les versions des pilotes et les progiciels, ont l'impact le plus important. Il est essentiel de sélectionner une version du LLM qui fonctionne sur différents équipements et de choisir une mesure de vitesse facilement compréhensible.
Nous avons choisi le nombre de jetons par seconde (jetons/s) comme mesure. Il est important de noter qu'un jeton ≠ un mot. Le LLM décompose les mots en éléments plus simples, typiques d'une langue spécifique, appelés "tokens".
La prévisibilité statistique du caractère suivant varie d'une langue à l'autre, de sorte que la tokenisation diffère. Par exemple, en anglais, environ 100 jetons sont dérivés de chaque 75 mots. Dans les langues utilisant l'alphabet cyrillique, le nombre de jetons par mot peut être plus élevé. Ainsi, 75 mots dans une langue cyrillique, comme le russe, peuvent correspondre à 120-150 tokens.
Vous pouvez vérifier cela en utilisant l'outil Tokenizer d'OpenAI. Il montre combien de tokens un fragment de texte est décomposé, ce qui fait du nombre de tokens par seconde un bon indicateur de la vitesse et des performances d'un LLM en matière de traitement du langage naturel.
Chaque test a été réalisé sur le système d'exploitation Ubuntu 22.04 LTS avec les pilotes NVIDIA® version 535.183.01 et la boîte à outils NVIDIA® CUDA® 12.5 installée. Des questions ont été formulées pour évaluer la qualité et la vitesse du LLM. La vitesse de traitement de chaque réponse a été enregistrée et contribuera à la valeur moyenne pour chaque configuration testée.
Nous avons commencé à tester différents GPU, des modèles les plus récents aux plus anciens. Une condition essentielle pour le test était de mesurer les performances d'un seul GPU, même si plusieurs étaient présents dans la configuration du serveur. En effet, les performances d'une configuration avec plusieurs GPU dépendent de facteurs supplémentaires tels que la présence d'une interconnexion à grande vitesse entre eux (NVLink).
Outre la vitesse, nous avons également tenté d'évaluer la qualité des réponses sur une échelle de 5 points, où 5 représente le meilleur résultat. Ces informations sont fournies ici à des fins de compréhension générale uniquement. À chaque fois, nous poserons les mêmes questions au réseau neuronal et tenterons de discerner avec quelle précision chacun d'entre eux comprend ce que l'utilisateur attend de lui.
Qwen 2
Récemment, une équipe de développeurs du groupe Alibaba a présenté la deuxième version de son réseau neuronal génératif Qwen. Il comprend 27 langues et est bien optimisé pour elles. Qwen 2 est disponible en différentes tailles afin de faciliter son déploiement sur n'importe quel appareil (des systèmes embarqués à ressources très limitées aux serveurs dédiés équipés de GPU) :
- 0.5B : adapté à l'IoT et aux systèmes embarqués ;
- 1.5B : une version étendue pour les systèmes embarqués, utilisée lorsque les capacités de 0.5B ne suffisent pas ;
- 7B : modèle de taille moyenne, bien adapté au traitement du langage naturel ;
- 57B : grand modèle haute performance adapté aux applications exigeantes ;
- 72B : le modèle ultime Qwen 2, conçu pour résoudre les problèmes les plus complexes et traiter de grands volumes de données.
Les versions 0.5B et 1.5B ont été entraînées sur des ensembles de données avec une longueur de contexte de 32K. Les versions 7B et 72B ont déjà été entraînées sur le contexte de 128K. Le modèle de compromis 57B a été entraîné sur des ensembles de données avec une longueur de contexte de 64K. Les créateurs positionnent Qwen 2 comme un analogue de Llama 3 capable de résoudre les mêmes problèmes, mais beaucoup plus rapidement.
Llama 3
La troisième version du réseau neuronal génératif de la famille MetaAI Llama a été introduite en avril 2024. Contrairement à Qwen 2, elle n'a été publiée qu'en deux versions : 8B et 70B. Ces modèles se positionnent comme un outil universel permettant de résoudre de nombreux problèmes dans des cas variés. Ils poursuivent la tendance au multilinguisme et à la multimodalité, tout en devenant plus rapides que les versions précédentes et en supportant une plus grande longueur de contexte.
Les créateurs de Llama 3 ont essayé d'affiner les modèles afin de réduire le pourcentage d'hallucinations statistiques et d'augmenter la variété des réponses. Llama 3 est donc tout à fait capable de donner des conseils pratiques, d'aider à rédiger une lettre d'affaires ou de spéculer sur un sujet spécifié par l'utilisateur. Les ensembles de données sur lesquels les modèles de Llama 3 ont été entraînés avaient une longueur de contexte de 128K et plus de 5% comprenaient des données en 30 langues. Toutefois, comme l'indique le communiqué de presse, les performances de génération en anglais seront nettement plus élevées que dans toute autre langue.
Comparaison
NVIDIA® RTX™ A6000
Commençons nos mesures de vitesse avec le GPU NVIDIA® RTX™ A6000, basé sur l'architecture Ampere (à ne pas confondre avec la NVIDIA® RTX™ A6000 Ada). Cette carte a des caractéristiques très modestes, mais en même temps, elle dispose de 48 Go de VRAM, ce qui lui permet de fonctionner avec des modèles de réseaux neuronaux assez importants. Malheureusement, la faible vitesse d'horloge et la bande passante sont les raisons de la faible vitesse d'inférence des LLM textuels.
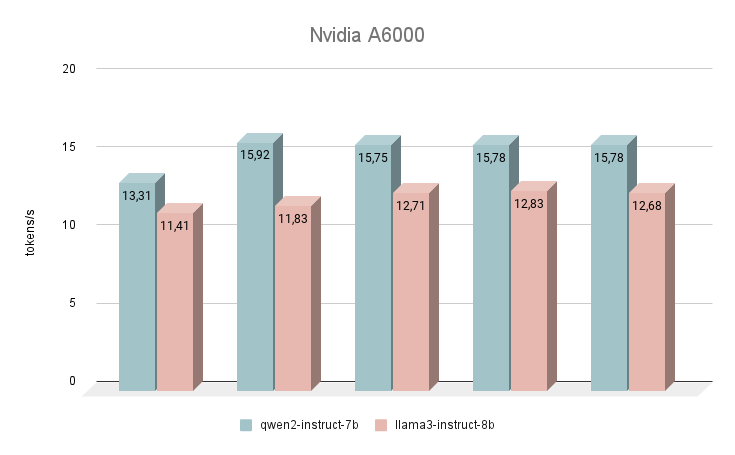
Immédiatement après le lancement, le réseau neuronal Qwen 2 a commencé à surpasser Llama 3. En répondant aux mêmes questions, la différence de vitesse moyenne était de 24 % en faveur de Qwen 2. La vitesse de génération des réponses était de l'ordre de 11 à 16 tokens par seconde. C'est 2 à 3 fois plus rapide que d'essayer d'exécuter la génération même sur un CPU puissant, mais dans notre classement, c'est le résultat le plus modeste.
NVIDIA® RTX™ 3090
Le prochain GPU est également construit sur l'architecture Ampere, a 2 fois moins de mémoire vidéo, mais en même temps, il fonctionne à une fréquence plus élevée (19500 MHz contre 16000 Mhz). La bande passante de la mémoire vidéo est également plus élevée (936,2 Go/s contre 768 Go/s). Ces deux facteurs augmentent considérablement les performances de la RTX™ 3090, même si l'on tient compte du fait qu'elle possède 256 cœurs CUDA® de moins.
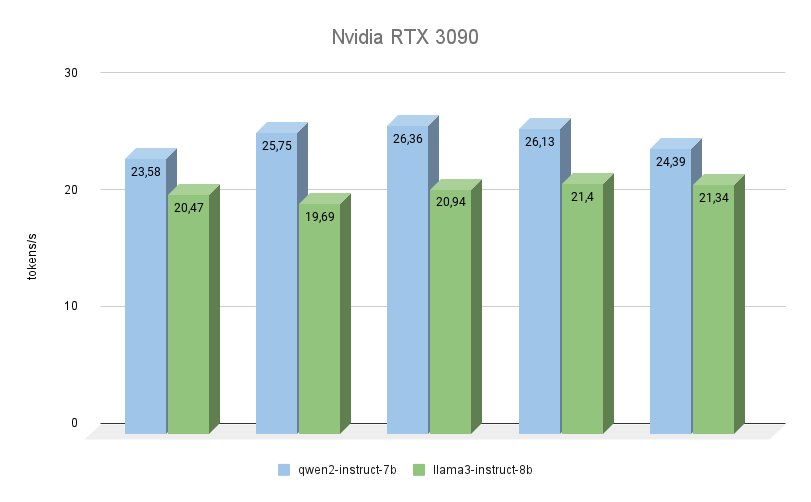
Ici, vous pouvez clairement voir que Qwen 2 est beaucoup plus rapide (jusqu'à 23%) que Llama 3 en effectuant les mêmes tâches. En ce qui concerne la qualité de la génération, le support multilingue de Qwen 3 est vraiment digne d'éloges, et le modèle répond toujours dans la même langue que celle dans laquelle la question a été posée. Avec Llama 3, à cet égard, il arrive souvent que le modèle comprenne la question elle-même, mais préfère formuler des réponses en anglais.
NVIDIA® RTX™ 4090
Voyons maintenant le plus intéressant : voyons comment la NVIDIA® RTX™ 4090, construite sur l'architecture Ada Lovelace, du nom de la mathématicienne anglaise Augusta Ada King, comtesse de Lovelace, s'acquitte de la même tâche. Elle est devenue célèbre pour avoir été la première programmeuse de l'histoire de l'humanité, et à l'époque où elle a écrit son premier programme, il n'existait pas d'ordinateur assemblé capable de l'exécuter. Cependant, il a été reconnu que l'algorithme décrit par Ada pour calculer les nombres de Bernoulli était le premier programme au monde écrit pour être joué sur un ordinateur.
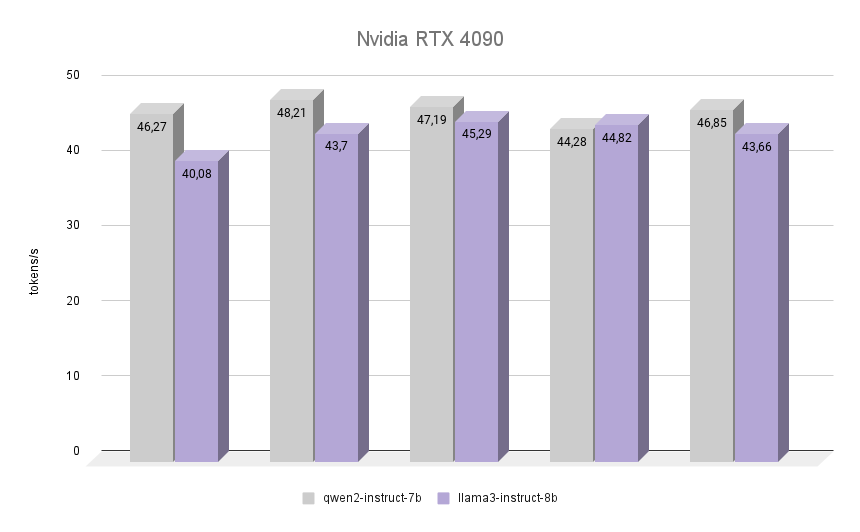
Le graphique montre clairement que la RTX™ 4090 a fait face à l'inférence des deux modèles presque deux fois plus vite. Il est intéressant de noter que dans l'une des itérations, le Llama 3 a réussi à surpasser le Qwen 2 de 1,2%. Toutefois, si l'on tient compte des autres itérations, le Qwen 2 a conservé sa position de leader, restant 7 % plus rapide que le Llama 3. Dans toutes les itérations, la qualité des réponses des deux réseaux neuronaux était élevée, avec un nombre minimum d'hallucinations. Le seul défaut est que, dans de rares cas, un ou deux caractères chinois ont été mélangés aux réponses, ce qui n'a en rien affecté le sens général.
NVIDIA® RTX™ A40
La prochaine carte NVIDIA® RTX™ A40, sur laquelle nous avons effectué des tests similaires, est à nouveau construite sur l'architecture Ampere et dispose de 48 Go de mémoire vidéo sur la carte mère. Par rapport à la RTX™ 3090, cette mémoire est légèrement plus rapide (20000 MHz contre 19500 MHz), mais sa bande passante est plus faible (695,8 Go/s contre 936,2 Go/s). Cette situation est compensée par le plus grand nombre de cœurs CUDA® (10752 contre 10496), ce qui permet à la RTX™ A40 d'être légèrement plus performante que la RTX™ 3090.
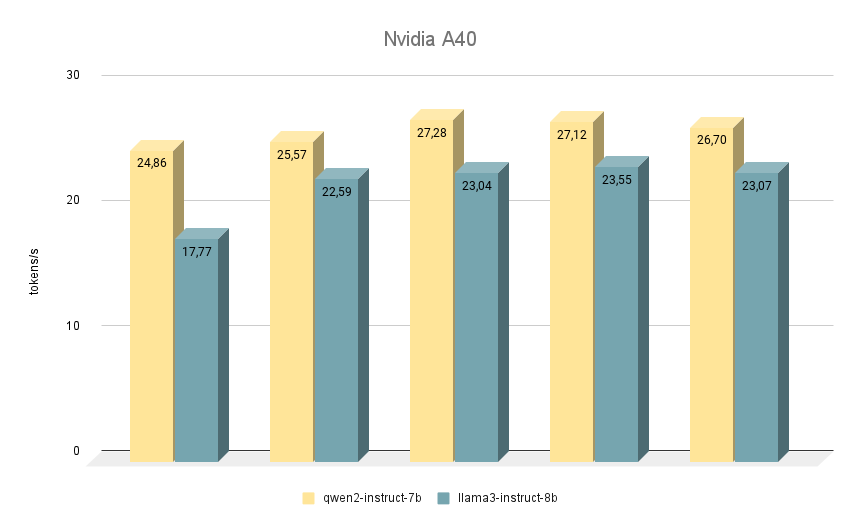
En ce qui concerne la comparaison de la vitesse des modèles, Qwen 2 devance également Llama 3 dans toutes les itérations. Lorsqu'il fonctionne sur la RTX™ A40, la différence de vitesse est d'environ 15% avec les mêmes réponses. Dans certaines tâches, Qwen 2 a donné un peu plus d'informations importantes, tandis que Llama 3 a été aussi précis que possible et a donné des exemples. Malgré cela, tout doit être revérifié, car parfois les deux modèles commencent à produire des réponses controversées.
NVIDIA® L20
Le dernier participant à notre test est le NVIDIA® L20. Ce GPU est construit comme la RTX™ 4090, sur l'architecture Ada Lovelace. Il s'agit d'un modèle assez récent, présenté à l'automne 2023. Il embarque 48 Go de mémoire vidéo et 11776 cœurs CUDA®. La bande passante mémoire est inférieure à celle de la RTX™ 4090 (864 Go/s contre 936,2 Go/s), tout comme la fréquence effective. Les scores d'inférence NVIDIA® L20 des deux modèles seront donc plus proches de 3090 que de 4090.
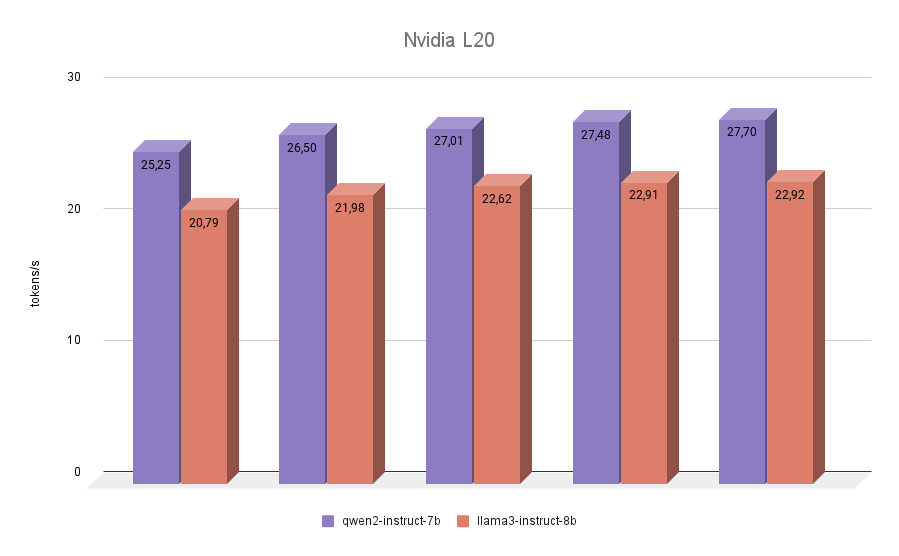
Le test final n'a pas apporté de surprises. Qwen 2 s'est avéré plus rapide que Llama 3 dans toutes les itérations.
Conclusion
Regroupons tous les résultats collectés dans un seul graphique. Qwen 2 a été plus rapide que Llama 3 de 7% à 24% selon le GPU utilisé. Sur la base de ces résultats, nous pouvons clairement conclure que si vous avez besoin d'obtenir une inférence rapide à partir de modèles tels que Qwen 2 ou Llama 3 sur des configurations mono-GPU, alors le leader incontesté sera la RTX™ 3090. Une alternative possible pourrait être l'A40 ou la L20. Mais il ne vaut pas la peine d'exécuter l'inférence de ces modèles sur des cartes Ampere de la génération A6000.

Nous n'avons délibérément pas mentionné les cartes avec une plus petite quantité de mémoire vidéo, par exemple la NVIDIA® RTX™ 2080Ti, dans les tests, car il n'est pas possible d'y adapter les modèles 7B ou 8B mentionnés ci-dessus sans quantification. Malheureusement, le modèle 1,5B Qwen 2 n'a pas de réponses de haute qualité et ne peut pas servir de remplacement complet pour le 7B.
Voir aussi:
Mis à jour: 04.01.2026
Publié: 20.01.2025




