





Votre propre Vicuna sous Linux

Cet article vous guidera à travers le processus de déploiement d'une alternative LLaMA de base sur un serveur LeaderGPU. Pour ce faire, nous utiliserons le projet FastChat et le modèle Vicuna disponible gratuitement.
Le modèle que nous utiliserons est basé sur l'architecture LLaMA de Meta mais a été optimisé pour un déploiement efficace sur du matériel grand public. Cette configuration offre un bon équilibre entre les performances et les besoins en ressources, ce qui la rend adaptée aux environnements de test et de production.
Préinstallation
Préparons l'installation de FastChat en mettant à jour le dépôt de cache des paquets :
sudo apt update && sudo apt -y upgradeInstallez automatiquement les pilotes NVIDIA® à l'aide de la commande suivante :
sudo ubuntu-drivers autoinstallVous pouvez également installer ces pilotes manuellement à l'aide de notre guide étape par étape. Redémarrez ensuite le serveur :
sudo shutdown -r nowL'étape suivante consiste à installer PIP (Package Installer for Python) :
sudo apt install python3-pipInstaller FastChat
Depuis PyPi
Il y a deux façons d'installer FastChat. Vous pouvez l'installer directement depuis PyPi :
pip3 install "fschat[model_worker,webui]"Depuis GitHub
Alternativement, vous pouvez cloner le dépôt FastChat depuis GitHub et l'installer :
git clone https://github.com/lm-sys/FastChat.gitcd FastChatN'oubliez pas de mettre à jour PIP avant de continuer :
pip3 install --upgrade pippip3 install -e ".[model_worker,webui]"Lancer FastChat
Premier départ
Pour assurer un lancement initial réussi, il est recommandé d'appeler manuellement FastChat directement depuis la ligne de commande :
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5Cette action récupère et télécharge automatiquement le modèle désigné de votre choix, qui doit être spécifié en utilisant le paramètre --model-path. Le 7b représente un modèle avec 7 milliards de paramètres. Il s'agit du modèle le plus léger, adapté aux GPU dotés de 16 Go de mémoire vidéo. Des liens vers des modèles avec un plus grand nombre de paramètres peuvent être trouvés dans le fichier Readme du projet.
Vous avez maintenant la possibilité d'engager une conversation avec le chatbot directement dans l'interface de ligne de commande ou de configurer une interface Web. Elle contient trois composants :
- Le contrôleur
- Travailleurs
- Serveur web Gradio
Mise en place des services
Transformons chaque composant en un service systemd séparé. Créez 3 fichiers séparés avec le contenu suivant :
sudo nano /etc/systemd/system/vicuna-controller.service[Unit]
Description=Vicuna controller service
[Service]
User=usergpu
WorkingDirectory=/home/usergpu
ExecStart=python3 -m fastchat.serve.controller
Restart=always
[Install]
WantedBy=multi-user.targetsudo nano /etc/systemd/system/vicuna-worker.service[Unit]
Description=Vicuna worker service
[Service]
User=usergpu
WorkingDirectory=/home/usergpu
ExecStart=python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5
Restart=always
[Install]
WantedBy=multi-user.targetsudo nano /etc/systemd/system/vicuna-webserver.service[Unit]
Description=Vicuna web server
[Service]
User=usergpu
WorkingDirectory=/home/usergpu
ExecStart=python3 -m fastchat.serve.gradio_web_server
Restart=always
[Install]
WantedBy=multi-user.targetSystemd met généralement à jour sa base de données de démons au cours du processus de démarrage du système. Cependant, vous pouvez le faire manuellement à l'aide de la commande suivante :
sudo systemctl daemon-reloadAjoutons maintenant trois nouveaux services au démarrage et lançons-les immédiatement à l'aide de l'option --now:
sudo systemctl enable vicuna-controller.service --now && sudo systemctl enable vicuna-worker.service --now && sudo systemctl enable vicuna-webserver.service --nowCependant, si vous tentez d'ouvrir une interface web à l'adresse http://[IP_ADDRESS]:7860, vous tomberez sur une interface totalement inutilisable, sans aucun modèle disponible. Pour résoudre ce problème, arrêtez le service d'interface web :
sudo systemctl stop vicuna-webserver.serviceExécutez le service web manuellement :
python3 -m fastchat.serve.gradio_web_serverAjouter une authentification
Cette action appelle un autre script, qui va enregistrer le modèle précédemment téléchargé dans une base de données interne de Gradio. Attendez quelques secondes et interrompez le processus en utilisant le raccourci Ctrl + C. Nous allons également nous occuper de la sécurité et activer un mécanisme d'authentification simple pour accéder à l'interface web. Ouvrez le fichier suivant si vous avez installé FastChat depuis PyPI :
sudo nano /home/usergpu/.local/lib/python3.10/site-packages/fastchat/serve/gradio_web_server.pyou
sudo nano /home/usergpu/FastChat/fastchat/serve/gradio_web_server.pyFaites défiler l'écran jusqu'à la fin. Trouvez cette ligne :
auth=auth,
Modifiez-la en définissant le nom d'utilisateur ou le mot de passe de votre choix :
auth=(“username”,”password”),Sauvegardez le fichier et quittez en utilisant le raccourci Ctrl + X. Enfin, démarrez l'interface web :
sudo systemctl start vicuna-webserver.serviceOuvrez http://[IP_ADDRESS]:7860 dans votre navigateur et profitez de FastChat avec Vicuna :
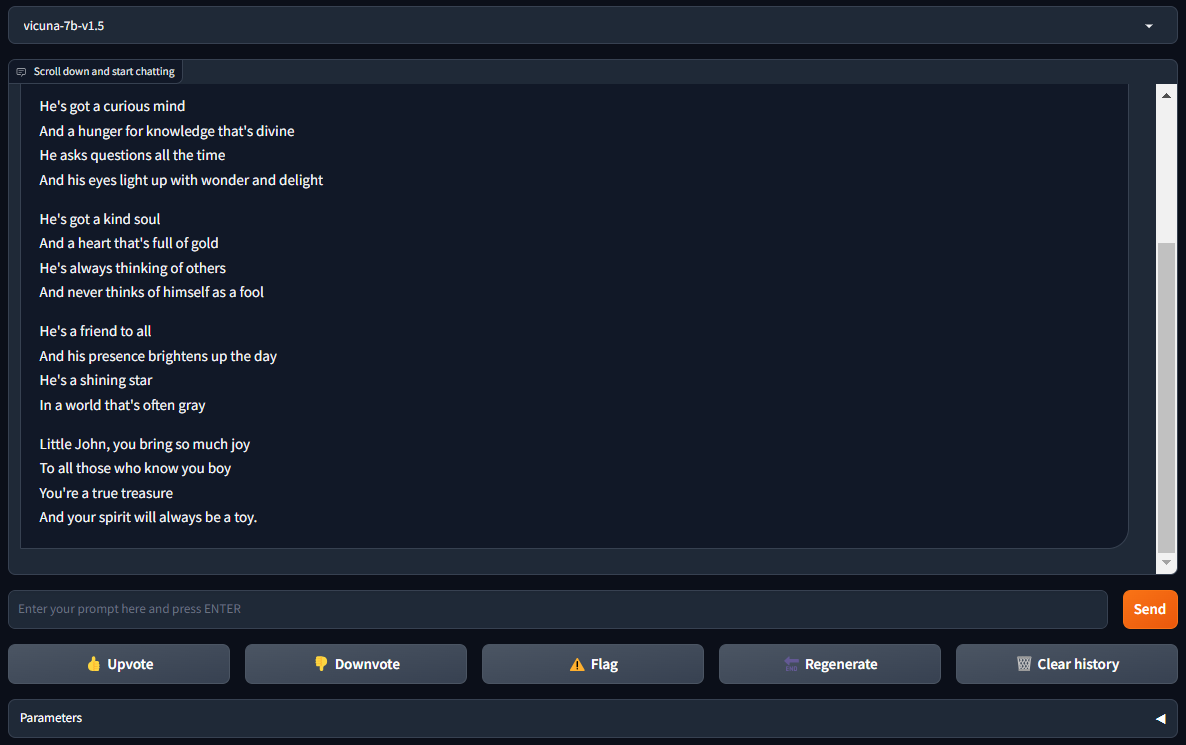
Voir aussi:
Mis à jour: 04.01.2026
Publié: 20.01.2025




