





Llama 3 utilisant Hugging Face

Le 18 avril 2024, le dernier modèle linguistique majeur de MetaAI, Llama 3, a été publié. Deux versions ont été présentées aux utilisateurs : 8B et 70B. La première version contient plus de 15 000 tokens et a été entraînée sur des données valables jusqu'en mars 2023. La seconde version, plus volumineuse, a été entraînée sur des données valables jusqu'en décembre 2023.
Étape 1. Préparer le système d'exploitation
Mise à jour du cache et des paquets
Mettons à jour le cache des paquets et mettons à niveau votre système d'exploitation avant de commencer à installer LLaMa 3. Veuillez noter que pour ce guide, nous utilisons Ubuntu 22.04 LTS comme système d'exploitation :
sudo apt update && sudo apt -y upgradeNous devons également ajouter Python Installer Packages (PIP), s'il n'est pas déjà présent dans le système :
sudo apt install python3-pipInstaller les pilotes NVIDIA®
Vous pouvez utiliser l'utilitaire automatisé qui est inclus par défaut dans les distributions Ubuntu :
sudo ubuntu-drivers autoinstallVous pouvez également installer les pilotes NVIDIA® manuellement. N'oubliez pas de redémarrer le serveur :
sudo shutdown -r nowÉtape 2. Obtenir le modèle
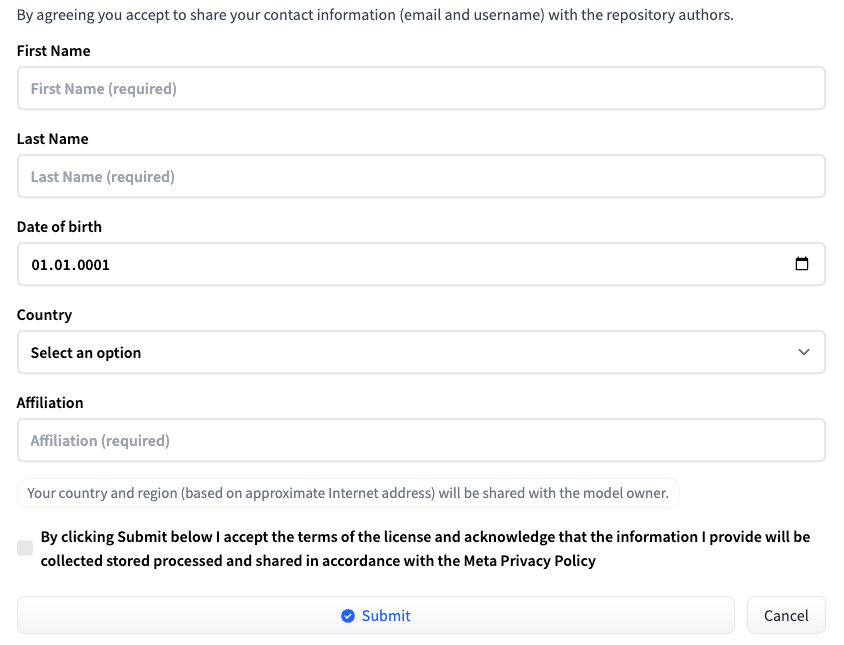
Connectez-vous à Hugging Face en utilisant votre nom d'utilisateur et votre mot de passe. Allez sur la page correspondant à la version LLM souhaitée : Meta-Llama-3-8B ou Meta-Llama-3-70B. Au moment de la publication de cet article, l'accès au modèle est fourni sur une base individuelle. Remplissez un court formulaire et cliquez sur le bouton Submit:
Demande d'accès à HF
Vous recevrez ensuite un message indiquant que votre demande a été soumise :
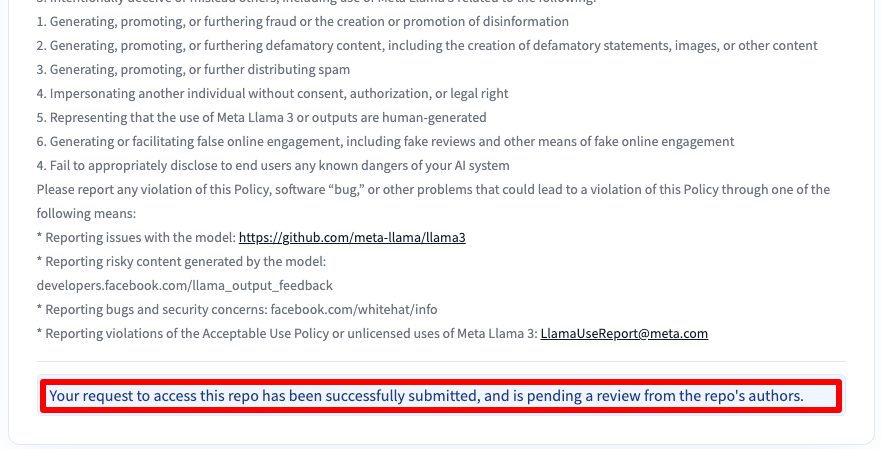
Vous obtiendrez l'accès après 30-40 minutes et en serez informé par e-mail.
Ajouter une clé SSH à HF
Générez et ajoutez une clé SSH que vous pourrez utiliser dans Hugging Face :
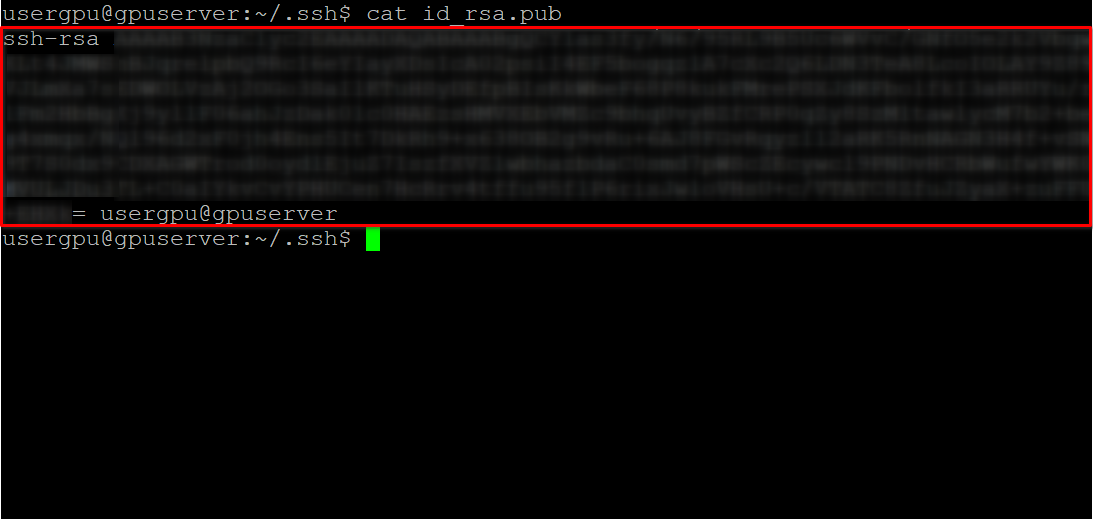
cd ~/.ssh && ssh-keygenLorsque la paire de clés est générée, vous pouvez afficher la clé publique dans l'émulateur de terminal :
cat id_rsa.pubCopiez toutes les informations commençant par ssh-rsa et se terminant par usergpu@gpuserver, comme indiqué dans la capture d'écran suivante :
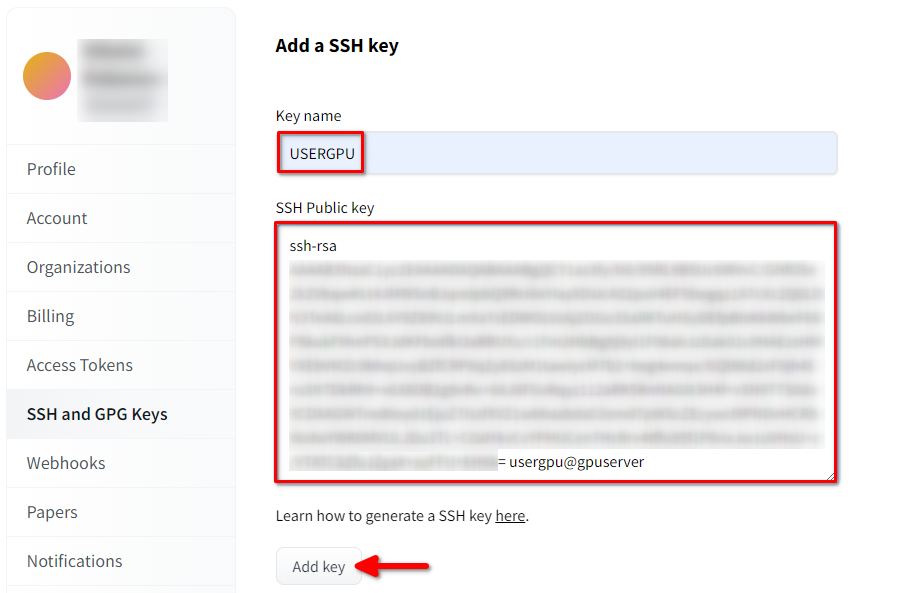
Ouvrez les paramètres du profil de Hugging Face. Choisissez ensuite SSH and GPG Keys et cliquez sur le bouton Ajouter une clé SSH :
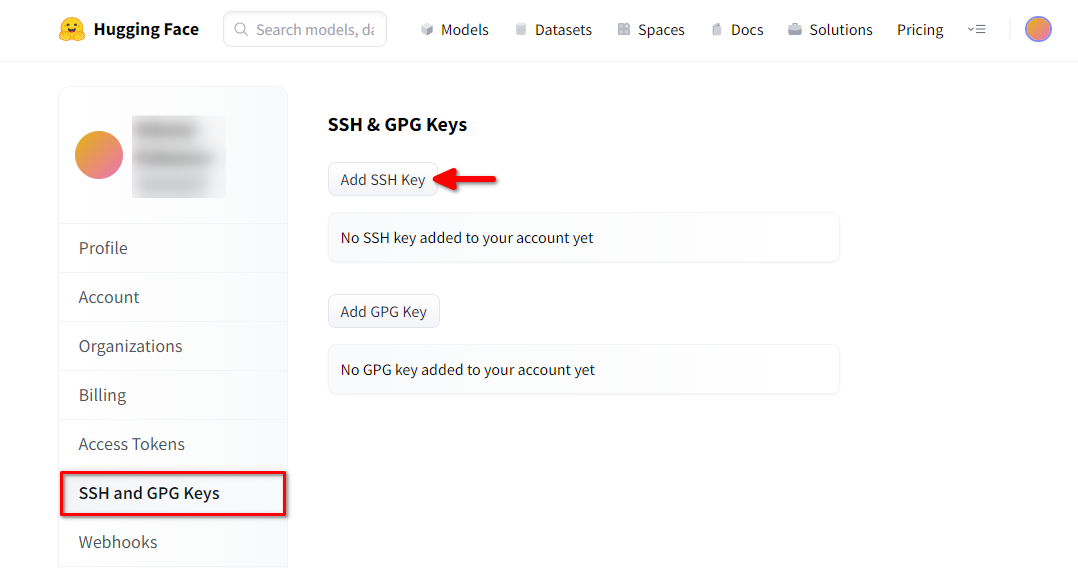
Remplissez le Key name et collez le SSH Public key copié depuis le terminal. Enregistrez la clé en appuyant sur Add key:
Maintenant, votre compte HF est lié à la clé SSH publique. La seconde partie (clé privée) est stockée sur le serveur. L'étape suivante consiste à installer une extension Git LFS (Large File Storage) spécifique, qui est utilisée pour télécharger des fichiers volumineux tels que des modèles de réseaux neuronaux. Ouvrez votre répertoire personnel :
cd ~/Téléchargez et exécutez le script shell. Ce script installe un nouveau dépôt tiers avec git-lfs :
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashVous pouvez maintenant l'installer à l'aide du gestionnaire de paquets standard :
sudo apt-get install git-lfsConfigurons git pour qu'il utilise notre pseudo HF :
git config --global user.name "John"Et lié au compte email HF :
git config --global user.email "john.doe@example.com"Télécharger le modèle
Ouvrir le répertoire cible :
cd /mnt/fastdiskEt commencez à télécharger le référentiel. Pour cet exemple, nous avons choisi la version 8B :
git clone git@hf.co:meta-llama/Meta-Llama-3-8BCe processus prend jusqu'à 5 minutes. Vous pouvez le surveiller en exécutant la commande suivante dans une autre console SSH :
watch -n 0.5 df -hVous verrez alors que l'espace libre sur le disque monté se réduit, ce qui garantit que le téléchargement progresse et que les données sont sauvegardées. L'état est actualisé toutes les demi-secondes. Pour arrêter manuellement la visualisation, appuyez sur le raccourci Ctrl + C.
Vous pouvez également installer btop et surveiller le processus à l'aide de cet utilitaire :
sudo apt -y install btop && btop
Pour quitter l'utilitaire btop, appuyez sur la touche Esc et sélectionnez Quit.
Étape 3. Exécuter le modèle
Ouvrez le répertoire :
cd /mnt/fastdiskTélécharger le dépôt Llama 3 :
git clone https://github.com/meta-llama/llama3Changez de répertoire :
cd llama3Exécuter l'exemple :
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir /mnt/fastdisk/Meta-Llama-3-8B/original \
--tokenizer_path /mnt/fastdisk/Meta-Llama-3-8B/original/tokenizer.model \
--max_seq_len 128 \
--max_batch_size 4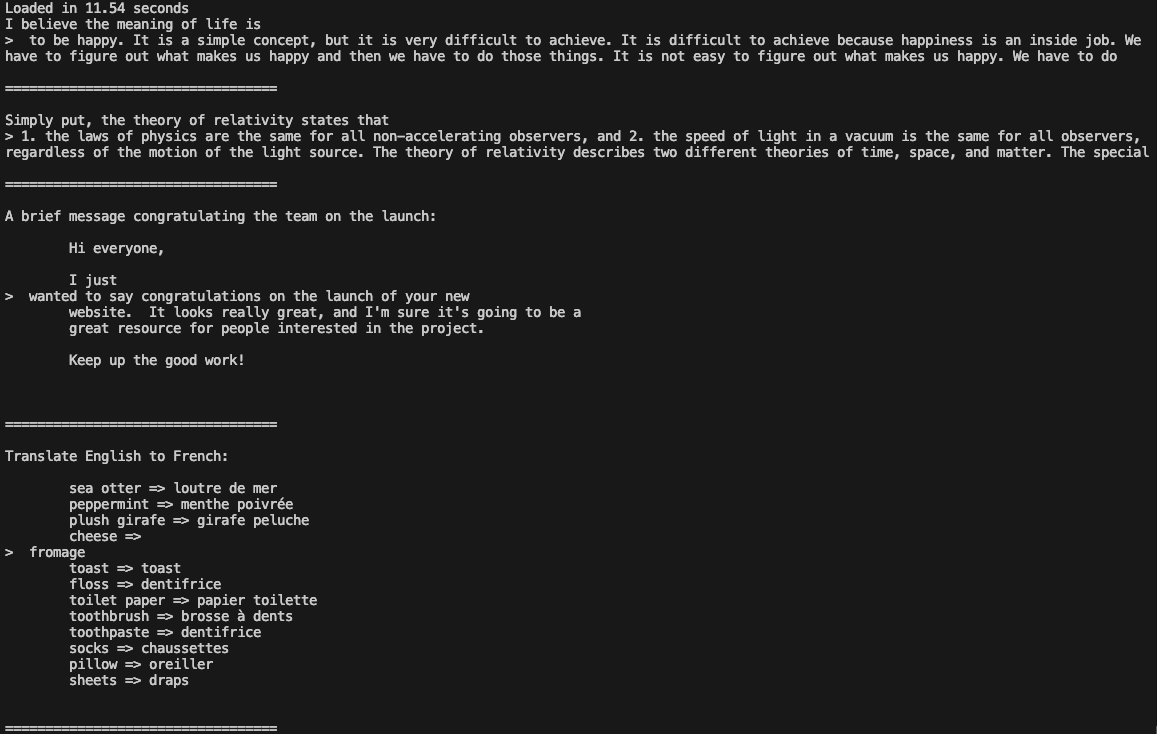
Vous pouvez maintenant utiliser Llama 3 dans vos applications.
Voir aussi:
Mis à jour: 04.01.2026
Publié: 20.01.2025




