





Votre propre Qwen utilisant HF

Les grands modèles de réseaux neuronaux, avec leurs capacités extraordinaires, sont fermement ancrés dans nos vies. Reconnaissant qu'il s'agit d'une opportunité de développement futur, les grandes entreprises ont commencé à développer leurs propres versions de ces modèles. Le géant chinois Alibaba n'est pas resté inactif. Il a créé son propre modèle, QWen (Tongyi Qianwen), qui est devenu la base de nombreux autres modèles de réseaux neuronaux.
Conditions préalables
Mettre à jour le cache et les paquets
Mettons à jour le cache des paquets et mettons à niveau votre système d'exploitation avant de commencer à configurer Qwen. Nous devons également ajouter les paquets d'installation Python (PIP), s'ils ne sont pas déjà présents dans le système. Veuillez noter que pour ce guide, nous utilisons Ubuntu 22.04 LTS comme système d'exploitation :
sudo apt update && sudo apt -y upgrade && sudo apt install python3-pipInstaller les pilotes NVIDIA®
Vous pouvez utiliser l'utilitaire automatisé qui est inclus par défaut dans les distributions Ubuntu :
sudo ubuntu-drivers autoinstallVous pouvez également installer les pilotes NVIDIA® manuellement à l'aide de notre guide étape par étape. N'oubliez pas de redémarrer le serveur :
sudo shutdown -r nowInterface web de génération de texte
Cloner le dépôt
Ouvrez le répertoire de travail sur le SSD :
cd /mnt/fastdiskCloner le référentiel du projet :
git clone https://github.com/oobabooga/text-generation-webui.gitInstaller les exigences
Ouvrir le répertoire téléchargé :
cd text-generation-webuiVérifier et installer tous les composants manquants :
pip install -r requirements.txtAjouter une clé SSH à HF
Avant de commencer, vous devez configurer la redirection de port (port distant 7860 vers 127.0.0.1:7860) dans votre client SSH. Vous trouverez des informations complémentaires dans l'article suivant : Se connecter à un serveur Linux.
Mettre à jour le dépôt de cache des paquets et les paquets installés :
sudo apt update && sudo apt -y upgradeGénérer et ajouter une clé SSH que vous pouvez utiliser dans Hugging Face :
cd ~/.ssh && ssh-keygenLorsque la paire de clés est générée, vous pouvez afficher la clé publique dans l'émulateur de terminal :
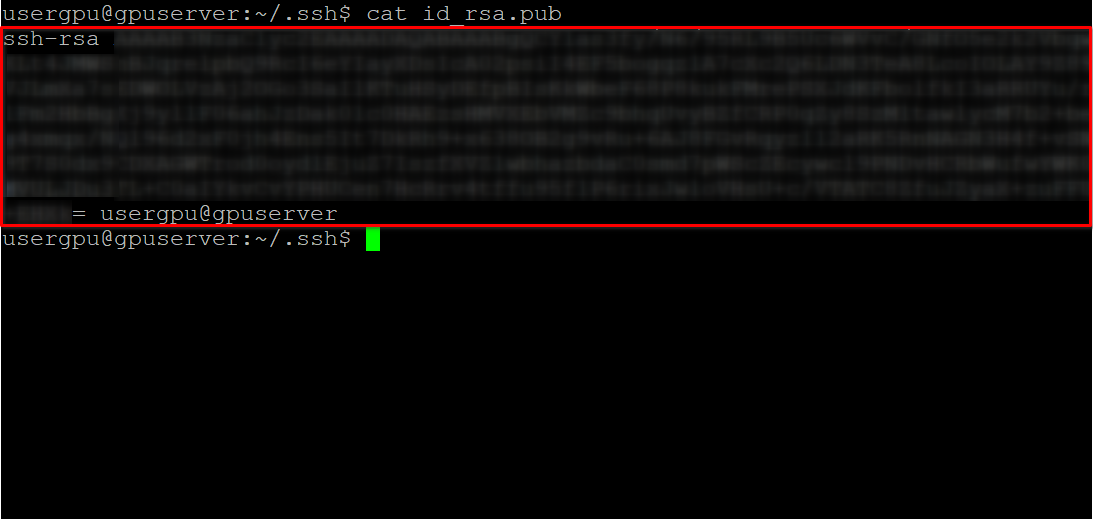
cat id_rsa.pubCopiez toutes les informations commençant par ssh-rsa et se terminant par usergpu@gpuserver comme indiqué dans la capture d'écran suivante :
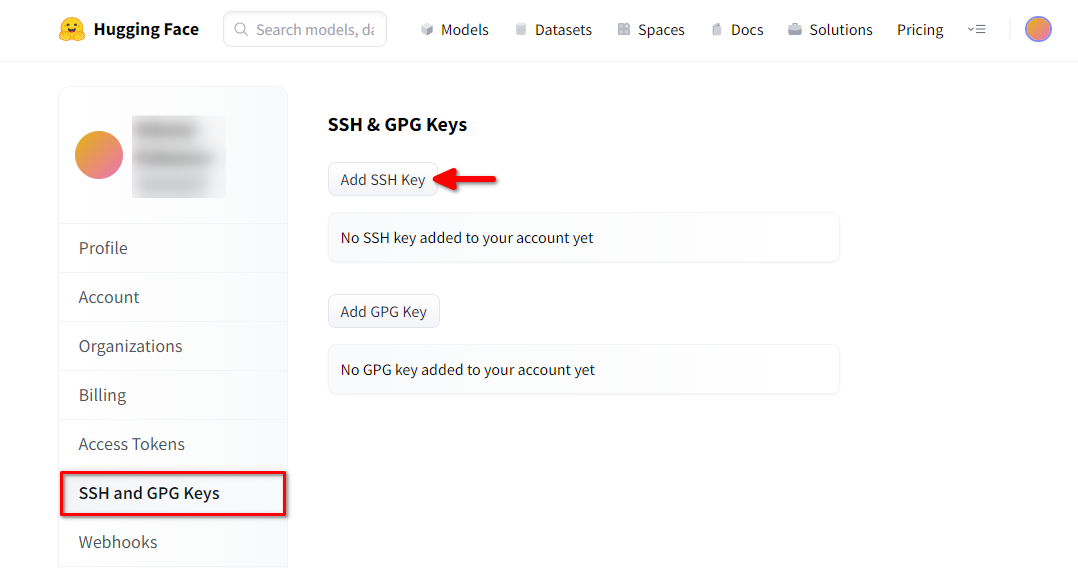
Ouvrez un navigateur web, tapez https://huggingface.co/ dans la barre d'adresse et appuyez sur Enter. Connectez-vous à votre compte HF et ouvrez les paramètres du profil. Choisissez ensuite SSH and GPG Keys et cliquez sur le bouton Add SSH Key:
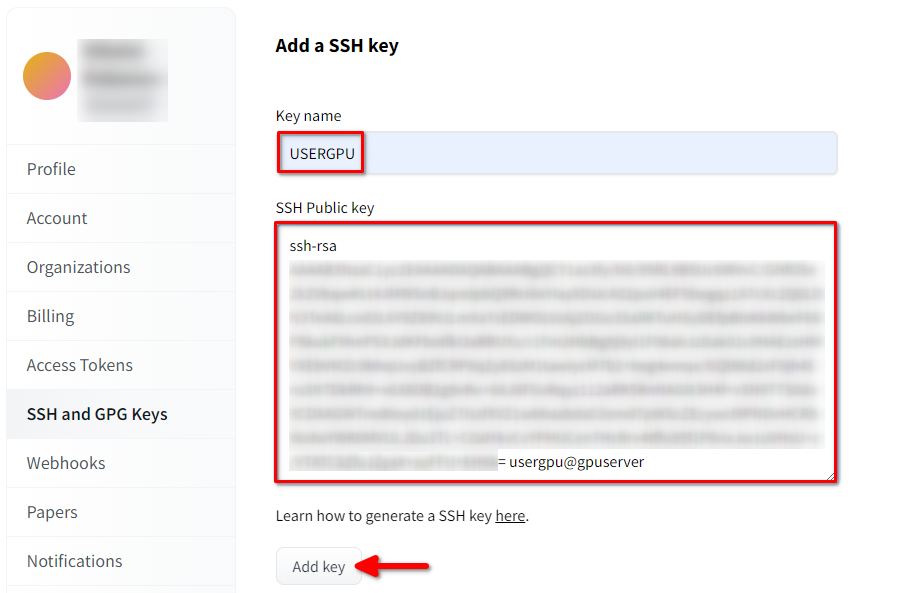
Remplissez le Key name et collez le SSH Public key copié depuis le terminal. Sauvegardez la clé en appuyant sur Add key:
Maintenant, votre compte HF est lié à la clé SSH publique. La seconde partie (clé privée) est stockée sur le serveur. L'étape suivante consiste à installer une extension Git LFS (Large File Storage) spécifique, qui est utilisée pour télécharger des fichiers volumineux tels que des modèles de réseaux neuronaux. Ouvrez votre répertoire personnel :
cd ~/Téléchargez et exécutez le script shell. Ce script installe un nouveau dépôt tiers avec git-lfs :
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashVous pouvez maintenant l'installer à l'aide du gestionnaire de paquets standard :
sudo apt-get install git-lfsConfigurons git pour qu'il utilise notre pseudo HF :
git config --global user.name "John"Et lié au compte email HF :
git config --global user.email "john.doe@example.com"Télécharger le modèle
L'étape suivante consiste à télécharger le modèle en utilisant la technique de clonage de référentiel couramment utilisée par les développeurs de logiciels. La seule différence est que le Git-LFS précédemment installé traitera automatiquement les fichiers pointeurs marqués et téléchargera tout le contenu. Ouvrez le répertoire nécessaire (/mnt/fastdisk dans notre exemple) :
cd /mnt/fastdiskCette commande peut prendre un certain temps :
git clone git@hf.co:Qwen/Qwen1.5-32B-Chat-GGUFExécuter le modèle
Exécuter un script qui démarrera le serveur web et spécifiera /mnt/fastdisk comme répertoire de travail avec les modèles. Ce script peut télécharger des composants supplémentaires lors du premier lancement.
./start_linux.sh --model-dir /mnt/fastdiskOuvrez votre navigateur web et sélectionnez le site llama.cpp dans la liste déroulante Model loader:
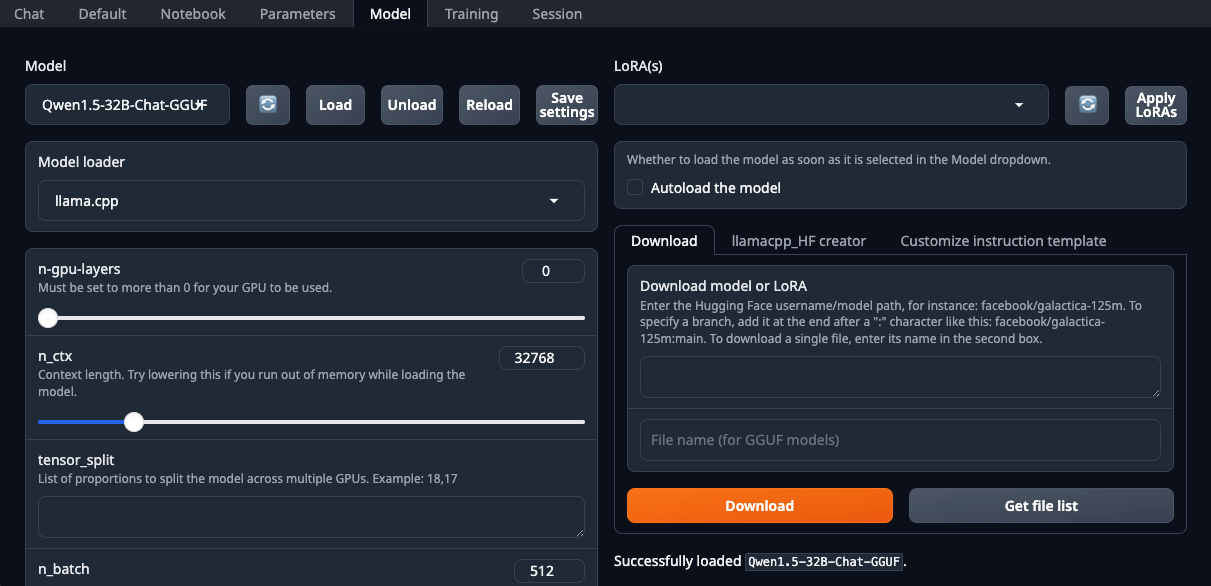
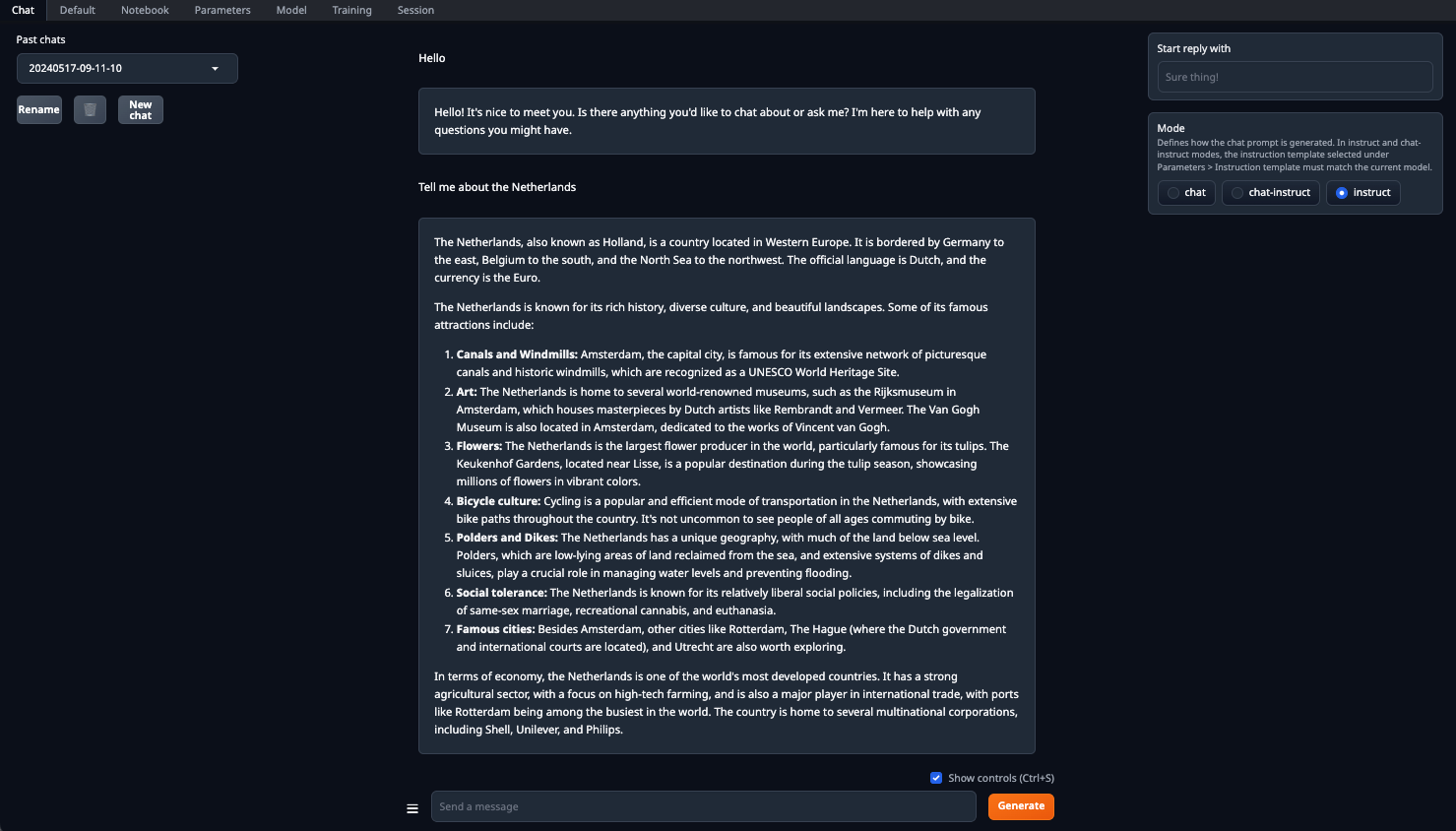
Veillez à définir le paramètre n-gpu-layers. C'est lui qui est responsable du pourcentage de calculs qui sera déchargé sur le GPU. Si vous laissez le chiffre à 0, tous les calculs seront effectués sur le CPU, ce qui est assez lent. Une fois tous les paramètres définis, cliquez sur le bouton Load. Ensuite, allez dans l'onglet Chat et sélectionnez Instruct mode. Vous pouvez maintenant saisir n'importe quel message et recevoir une réponse :
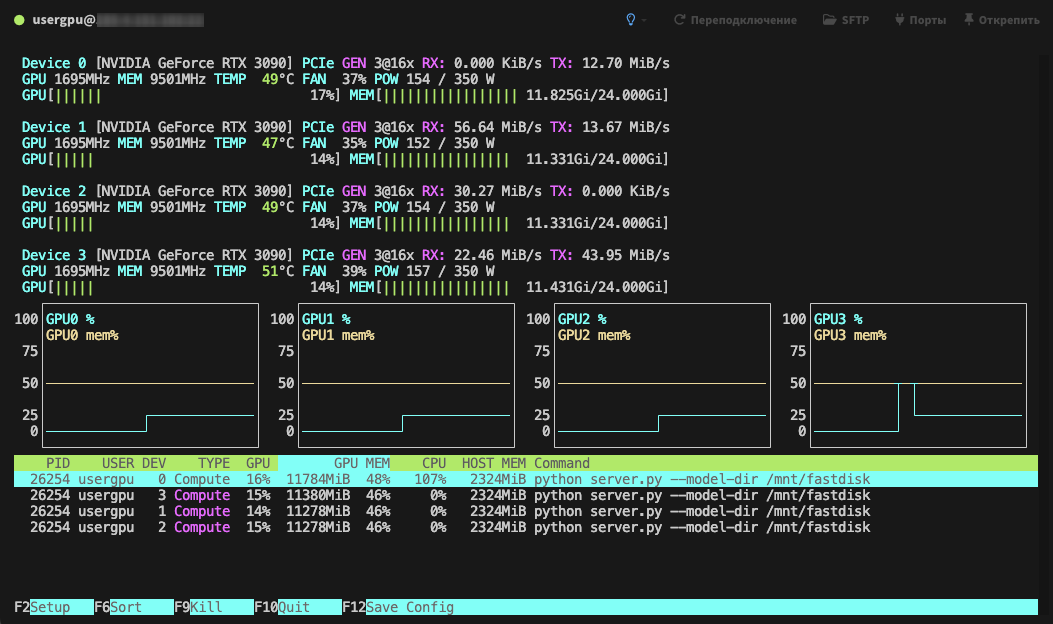
Le traitement sera effectué par défaut sur tous les GPU disponibles, en tenant compte des paramètres spécifiés précédemment :
Voir aussi:
Mis à jour: 04.01.2026
Publié: 20.01.2025




