





Qu'est-ce que la distillation des connaissances ?
Les grands modèles linguistiques (LLM) font désormais partie intégrante de notre vie grâce à leurs capacités uniques. Ils comprennent le contexte et génèrent des textes cohérents et détaillés sur cette base. Ils peuvent traiter et répondre dans n'importe quelle langue tout en tenant compte des nuances culturelles de chacune d'entre elles.
Les LLM excellent dans la résolution de problèmes complexes, la programmation, les conversations, etc. Cette polyvalence provient du traitement de grandes quantités de données de formation, d'où le terme "large". Ces modèles peuvent contenir des dizaines ou des centaines de milliards de paramètres, ce qui les rend gourmands en ressources pour une utilisation quotidienne.
La formation est le processus le plus exigeant. Les modèles de réseaux neuronaux apprennent en traitant d'énormes ensembles de données, en ajustant leurs "poids" internes pour former des connexions stables entre les neurones. Ces connexions stockent des connaissances que le réseau neuronal formé peut ensuite utiliser sur des appareils finaux.
Toutefois, la plupart des terminaux ne disposent pas de la puissance de calcul nécessaire pour faire fonctionner ces modèles. Par exemple, l'exécution de la version complète de Llama 2 (70B paramètres) nécessite un GPU avec 48 Go de mémoire vidéo, un matériel dont peu d'utilisateurs disposent à la maison, et encore moins sur des appareils mobiles.
Par conséquent, la plupart des réseaux neuronaux modernes fonctionnent dans une infrastructure en nuage plutôt que sur des appareils portables, qui y accèdent par l'intermédiaire d'API. Néanmoins, les fabricants d'appareils progressent de deux manières : en équipant les appareils d'unités de calcul spécialisées telles que les NPU et en développant des méthodes pour améliorer les performances des modèles de réseaux neuronaux compacts.
Réduire la taille
Couper l'excédent
La quantification est la première méthode, et la plus efficace, de réduction de la taille des réseaux neuronaux. Les poids des réseaux neuronaux utilisent généralement des nombres à virgule flottante de 32 bits, mais il est possible de les réduire en modifiant ce format. L'utilisation de valeurs de 8 bits (ou même de valeurs binaires dans certains cas) peut décupler la taille du réseau, bien que la précision des réponses s'en trouve considérablement réduite.
L'élagage est une autre approche qui consiste à supprimer les connexions sans importance dans le réseau neuronal. Ce processus fonctionne à la fois pendant la formation et avec les réseaux terminés. Au-delà des simples connexions, l'élagage peut supprimer des neurones ou des couches entières. Cette réduction des paramètres et des connexions permet de diminuer les besoins en mémoire.
La décomposition matricielle ou tensorielle est la troisième technique courante de réduction de la taille. La décomposition d'une grande matrice en un produit de trois matrices plus petites permet de réduire le nombre total de paramètres tout en maintenant la qualité. La taille du réseau peut ainsi être réduite des dizaines de fois. La décomposition tensorielle offre des résultats encore meilleurs, bien qu'elle nécessite davantage d'hyperparamètres.
Bien que ces méthodes réduisent efficacement la taille, elles sont toutes confrontées au problème de la perte de qualité. Les modèles compressés de grande taille sont plus performants que leurs homologues plus petits non compressés, mais chaque compression risque de réduire la précision de la réponse. La distillation des connaissances représente une tentative intéressante d'équilibrer la qualité et la taille.
Essayons ensemble
La distillation des connaissances s'explique le mieux par l'analogie entre un étudiant et un enseignant. Tandis que les étudiants apprennent, les enseignants enseignent et mettent continuellement à jour leurs connaissances. Lorsque tous deux sont confrontés à de nouvelles connaissances, l'enseignant a un avantage, car il peut s'appuyer sur ses vastes connaissances dans d'autres domaines, alors que l'étudiant ne dispose pas encore de cette base.
Ce principe s'applique aux réseaux neuronaux. Lorsque l'on entraîne deux réseaux neuronaux du même type mais de tailles différentes sur des données identiques, le réseau le plus grand obtient généralement de meilleurs résultats. Sa plus grande capacité de "connaissance" lui permet d'obtenir des réponses plus précises que son homologue plus petit. Cela soulève une question intéressante : pourquoi ne pas entraîner le petit réseau non seulement sur l'ensemble des données, mais aussi sur les résultats plus précis du grand réseau ?
Ce processus est la distillation des connaissances : une forme d'apprentissage supervisé où un modèle plus petit apprend à reproduire les prédictions d'un modèle plus grand. Si cette technique permet de compenser la perte de qualité due à la réduction de la taille des réseaux neuronaux, elle nécessite des ressources informatiques et un temps de formation supplémentaires.
Logiciel et logique
Les fondements théoriques étant désormais clairs, examinons le processus d'un point de vue technique. Nous commencerons par les outils logiciels qui peuvent vous guider tout au long des étapes de formation et de distillation des connaissances.
Python, avec la bibliothèque TorchTune de l'écosystème PyTorch, offre l'approche la plus simple pour étudier et affiner de grands modèles de langage. Voici comment fonctionne l'application :
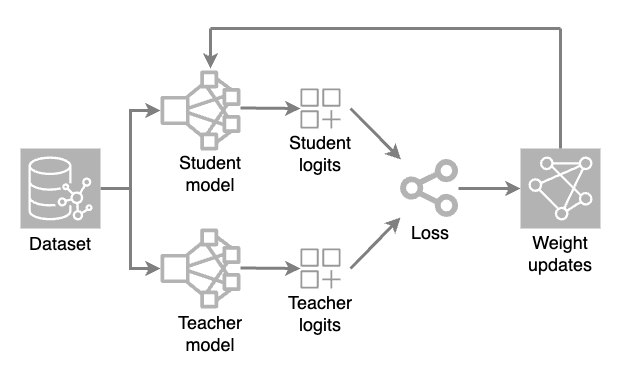
Deux modèles sont chargés : un modèle complet (enseignant) et un modèle réduit (élève). Au cours de chaque itération de formation, le modèle de l'enseignant génère des prédictions à haute température tandis que le modèle de l'étudiant traite l'ensemble de données pour faire ses propres prédictions.
Les valeurs de sortie brutes (logits) des deux modèles sont évaluées à l'aide d'une fonction de perte (une mesure numérique de l'écart d'une prédiction par rapport à la valeur correcte). Des ajustements de poids sont ensuite appliqués au modèle de l'élève par rétropropagation. Cela permet au petit modèle d'apprendre et de reproduire les prédictions du modèle de l'enseignant.
Le principal fichier de configuration dans le code de l'application est appelé "recette". Ce fichier stocke tous les paramètres et réglages de la distillation, ce qui rend les expériences reproductibles et permet aux chercheurs de suivre l'influence des différents paramètres sur le résultat final.
Lors de la sélection des valeurs des paramètres et des nombres d'itérations, il est essentiel de maintenir un équilibre. Un modèle trop distillé risque de perdre sa capacité à reconnaître les détails subtils et le contexte, et d'adopter par défaut des réponses toutes faites. Bien qu'il soit pratiquement impossible d'atteindre un équilibre parfait, un suivi attentif du processus de distillation peut améliorer considérablement la qualité de prédiction des modèles de réseaux neuronaux, même les plus modestes.
Il convient également de prêter attention au suivi pendant le processus de formation. Cela permettra d'identifier les problèmes à temps et de les corriger rapidement. Pour ce faire, vous pouvez utiliser l'outil TensorBoard. Il s'intègre parfaitement aux projets PyTorch et vous permet d'évaluer visuellement de nombreuses mesures, telles que la précision et les pertes. En outre, il vous permet de construire un graphique de modèle, de suivre l'utilisation de la mémoire et le temps d'exécution des opérations.
Conclusion
La distillation des connaissances est une méthode efficace pour optimiser les réseaux neuronaux afin d'améliorer les modèles compacts. Elle donne de meilleurs résultats lorsqu'il est essentiel d'équilibrer les performances et la qualité des réponses.
Bien que la distillation des connaissances nécessite un suivi attentif, ses résultats peuvent être remarquables. Les modèles deviennent beaucoup plus petits tout en maintenant la qualité de la prédiction, et ils fonctionnent mieux avec moins de ressources informatiques.
Lorsqu'elle est bien planifiée avec des paramètres appropriés, la distillation des connaissances est un outil essentiel pour créer des réseaux neuronaux compacts sans sacrifier la qualité.
Voir aussi:
Mis à jour: 04.01.2026
Publié: 23.01.2025




